GensimによるWord2Vecの学習と使用#
前章でCBOWモデルを実装することでword2vecの仕組みを学びました。実際に、その以外、word2vecの関して様々な取り組みがあります。
Skip-gramモデルでは、ターゲットからコンテキストを推測するタスクを構築しています
Negative Samplingという新しい損失関数を導入することで学習の高速化を図る
応用の視点から、これらの手法をすべでゼロから実装することが難しいので、gensimというライブラリを使って、Word2Vecモデルを学習、管理、使用することは、多くの自然言語処理タスクにおいて効果的な選択肢となります。
#!pip install --upgrade gensim
#!pip install mecab-python3
#!pip install unidic-lite
Gensimの使い方#
Gensimによる学習#
from gensim.models import Word2Vec
sample_sents = [['you', 'say', 'goodbye', 'and', 'I', "say", "hello" '.']]
model = Word2Vec(sentences=sample_sents, vector_size=5, window=1, min_count=1)
model.wv['you']
array([-0.06810732, -0.01892803, 0.11537147, -0.15043275, -0.07872207],
dtype=float32)
オプション |
説明 |
|---|---|
sentences |
元となるコーパス.単語リストのリスト. |
corpus_file |
コーパスをファイル読み込みする場合に指定.1行1文の形式で,単語は空白区切りで認識される. |
vector_size |
分散表現の次元.リファレンスではvector_sizeと書いてあるように見えるが,sizeでないと動かない. |
window |
学習時に利用されるコンテキストの長さ. |
min_count |
分散表現を獲得する単語の最小頻度 |
workers |
学習時の使用スレッド数. |
sg |
学習アルゴリズムの選択.\(1\)ならskip-gram,\(0\)ならCBOW. |
with open('./Data/lee_background.cor', 'r') as file:
corpus = file.readlines()
processed_corpus = [line.lower().split() for line in corpus]
model = Word2Vec(
sentences=processed_corpus, # 学習対象のコーパス
vector_size=100, # 埋め込みベクトルの次元数
window=5, # コンテキストウィンドウのサイズ
min_count=5, # 登場頻度が5未満の単語は無視
sg=1, # 1でskip-gramを使用(0ならCBOW)
negative=5 # negative samplingのサンプル数
)
Gensimによる日本語モデル学習#
import MeCab
def tokenize(text):
""" テキストを形態素解析して、トークンのリストを返す """
mecab = MeCab.Tagger("-Owakati")
return mecab.parse(text).strip().split()
documents = ["これはサンプルの文書です。", "Word2Vecの学習を行います。"]
# 形態素解析を行い、単語リストに変換
tokenized_documents = [tokenize(doc) for doc in documents]
# Word2Vecモデルの訓練
model_jp = Word2Vec(sentences=tokenized_documents, vector_size=100, window=5, min_count=1, workers=4)
日本語のコーパスデータを用いて、Word2Vecモデルを学習してください。
モデルの使い方#
モデルには,wvというオブジェクトに単語と単語分散表現の情報が格納されています。さらに、学習済みの単語ベクトルにアクセスし、それらを操作するための主要なインターフェースを提供します。
単語ベクトルの取得:
model.wv['word']で特定の単語のベクトルを取得できます。
model.wv['you']
array([ 0.19337663, 0.09774637, 0.08230773, 0.08041722, 0.02691096,
-0.29350522, 0.11445814, 0.35743073, -0.12076563, -0.16577783,
-0.08010983, -0.2872734 , -0.18047102, 0.1226377 , 0.00102022,
-0.01850658, 0.07040613, 0.02790923, -0.01584491, -0.24144535,
-0.04051629, -0.01214796, 0.08720642, -0.11906351, -0.13813414,
-0.04226959, -0.36278018, -0.2306583 , -0.04567106, -0.00360748,
0.17834684, -0.02556978, 0.26564252, -0.37816748, 0.02364997,
0.12341089, 0.03853341, -0.1442697 , -0.22497116, -0.26916572,
0.03460971, -0.03341158, -0.00745787, 0.08399593, 0.03590654,
0.01921166, -0.18919708, -0.11792235, 0.04861519, 0.15303735,
-0.01347453, -0.02740923, -0.15427947, 0.02579713, -0.06468962,
-0.09894565, 0.09752399, -0.01547151, -0.23212026, 0.10565163,
0.00067751, 0.08665007, -0.2282535 , 0.12337249, -0.22885354,
0.22695038, -0.01945649, 0.05462346, -0.23896529, 0.11462793,
-0.20084551, -0.08738026, 0.1547769 , -0.09788508, 0.26543298,
-0.02979359, 0.00125812, 0.12162155, -0.252121 , -0.06679838,
-0.2631262 , 0.00387961, -0.05465286, 0.17661253, 0.01188976,
0.07656693, 0.05598635, 0.08212705, 0.23733304, -0.02769101,
0.17985067, 0.01469264, -0.03217191, -0.02709124, 0.19190803,
0.08791966, -0.13138732, -0.02569338, -0.01334047, 0.04408439],
dtype=float32)
類似度の計算:
model.wv.similarity('word1', 'word2')で2つの単語間の類似度を計算できます。
model.wv.similarity("you", "your")
0.9647207
最も類似した単語の取得:
model.wv.most_similar('word')で特定の単語に最も類似した単語を取得できます
model.wv.most_similar("you")
[("don't", 0.992469847202301),
('"we', 0.9898550510406494),
('what', 0.9895883798599243),
('know', 0.9890603423118591),
("it's", 0.9877724647521973),
('can', 0.9864660501480103),
('do', 0.98585444688797),
('so', 0.9854378700256348),
('"i', 0.9847905039787292),
('get', 0.9843558073043823)]
Note
Gensimで学習済みモデルを使用する方法は、モデルの種類と読み込み方法によって異なります。通常は、通常はwvを介してベクトルにアクセスしますが、KeyedVectorsを使用する場合、KeyedVectors自体が単語ベクトルへの直接アクセスを提供するので、wvは不要です。
モデルの管理#
# モデルの保存と読み込み
#model.save("word2vec.model")
#model = Word2Vec.load("word2vec.model")
学習済みモデルの読み込み#
Gensimはいくつかの学習済みモデルを提供して、簡単に読み込むことができます。
import gensim.downloader
print(list(gensim.downloader.info()['models'].keys()))
['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis']
model = gensim.downloader.load('word2vec-google-news-300')
similarity = model.similarity('woman', 'man')
similarity
0.76640123
model['king']
array([ 1.25976562e-01, 2.97851562e-02, 8.60595703e-03, 1.39648438e-01,
-2.56347656e-02, -3.61328125e-02, 1.11816406e-01, -1.98242188e-01,
5.12695312e-02, 3.63281250e-01, -2.42187500e-01, -3.02734375e-01,
-1.77734375e-01, -2.49023438e-02, -1.67968750e-01, -1.69921875e-01,
3.46679688e-02, 5.21850586e-03, 4.63867188e-02, 1.28906250e-01,
1.36718750e-01, 1.12792969e-01, 5.95703125e-02, 1.36718750e-01,
1.01074219e-01, -1.76757812e-01, -2.51953125e-01, 5.98144531e-02,
3.41796875e-01, -3.11279297e-02, 1.04492188e-01, 6.17675781e-02,
1.24511719e-01, 4.00390625e-01, -3.22265625e-01, 8.39843750e-02,
3.90625000e-02, 5.85937500e-03, 7.03125000e-02, 1.72851562e-01,
1.38671875e-01, -2.31445312e-01, 2.83203125e-01, 1.42578125e-01,
3.41796875e-01, -2.39257812e-02, -1.09863281e-01, 3.32031250e-02,
-5.46875000e-02, 1.53198242e-02, -1.62109375e-01, 1.58203125e-01,
-2.59765625e-01, 2.01416016e-02, -1.63085938e-01, 1.35803223e-03,
-1.44531250e-01, -5.68847656e-02, 4.29687500e-02, -2.46582031e-02,
1.85546875e-01, 4.47265625e-01, 9.58251953e-03, 1.31835938e-01,
9.86328125e-02, -1.85546875e-01, -1.00097656e-01, -1.33789062e-01,
-1.25000000e-01, 2.83203125e-01, 1.23046875e-01, 5.32226562e-02,
-1.77734375e-01, 8.59375000e-02, -2.18505859e-02, 2.05078125e-02,
-1.39648438e-01, 2.51464844e-02, 1.38671875e-01, -1.05468750e-01,
1.38671875e-01, 8.88671875e-02, -7.51953125e-02, -2.13623047e-02,
1.72851562e-01, 4.63867188e-02, -2.65625000e-01, 8.91113281e-03,
1.49414062e-01, 3.78417969e-02, 2.38281250e-01, -1.24511719e-01,
-2.17773438e-01, -1.81640625e-01, 2.97851562e-02, 5.71289062e-02,
-2.89306641e-02, 1.24511719e-02, 9.66796875e-02, -2.31445312e-01,
5.81054688e-02, 6.68945312e-02, 7.08007812e-02, -3.08593750e-01,
-2.14843750e-01, 1.45507812e-01, -4.27734375e-01, -9.39941406e-03,
1.54296875e-01, -7.66601562e-02, 2.89062500e-01, 2.77343750e-01,
-4.86373901e-04, -1.36718750e-01, 3.24218750e-01, -2.46093750e-01,
-3.03649902e-03, -2.11914062e-01, 1.25000000e-01, 2.69531250e-01,
2.04101562e-01, 8.25195312e-02, -2.01171875e-01, -1.60156250e-01,
-3.78417969e-02, -1.20117188e-01, 1.15234375e-01, -4.10156250e-02,
-3.95507812e-02, -8.98437500e-02, 6.34765625e-03, 2.03125000e-01,
1.86523438e-01, 2.73437500e-01, 6.29882812e-02, 1.41601562e-01,
-9.81445312e-02, 1.38671875e-01, 1.82617188e-01, 1.73828125e-01,
1.73828125e-01, -2.37304688e-01, 1.78710938e-01, 6.34765625e-02,
2.36328125e-01, -2.08984375e-01, 8.74023438e-02, -1.66015625e-01,
-7.91015625e-02, 2.43164062e-01, -8.88671875e-02, 1.26953125e-01,
-2.16796875e-01, -1.73828125e-01, -3.59375000e-01, -8.25195312e-02,
-6.49414062e-02, 5.07812500e-02, 1.35742188e-01, -7.47070312e-02,
-1.64062500e-01, 1.15356445e-02, 4.45312500e-01, -2.15820312e-01,
-1.11328125e-01, -1.92382812e-01, 1.70898438e-01, -1.25000000e-01,
2.65502930e-03, 1.92382812e-01, -1.74804688e-01, 1.39648438e-01,
2.92968750e-01, 1.13281250e-01, 5.95703125e-02, -6.39648438e-02,
9.96093750e-02, -2.72216797e-02, 1.96533203e-02, 4.27246094e-02,
-2.46093750e-01, 6.39648438e-02, -2.25585938e-01, -1.68945312e-01,
2.89916992e-03, 8.20312500e-02, 3.41796875e-01, 4.32128906e-02,
1.32812500e-01, 1.42578125e-01, 7.61718750e-02, 5.98144531e-02,
-1.19140625e-01, 2.74658203e-03, -6.29882812e-02, -2.72216797e-02,
-4.82177734e-03, -8.20312500e-02, -2.49023438e-02, -4.00390625e-01,
-1.06933594e-01, 4.24804688e-02, 7.76367188e-02, -1.16699219e-01,
7.37304688e-02, -9.22851562e-02, 1.07910156e-01, 1.58203125e-01,
4.24804688e-02, 1.26953125e-01, 3.61328125e-02, 2.67578125e-01,
-1.01074219e-01, -3.02734375e-01, -5.76171875e-02, 5.05371094e-02,
5.26428223e-04, -2.07031250e-01, -1.38671875e-01, -8.97216797e-03,
-2.78320312e-02, -1.41601562e-01, 2.07031250e-01, -1.58203125e-01,
1.27929688e-01, 1.49414062e-01, -2.24609375e-02, -8.44726562e-02,
1.22558594e-01, 2.15820312e-01, -2.13867188e-01, -3.12500000e-01,
-3.73046875e-01, 4.08935547e-03, 1.07421875e-01, 1.06933594e-01,
7.32421875e-02, 8.97216797e-03, -3.88183594e-02, -1.29882812e-01,
1.49414062e-01, -2.14843750e-01, -1.83868408e-03, 9.91210938e-02,
1.57226562e-01, -1.14257812e-01, -2.05078125e-01, 9.91210938e-02,
3.69140625e-01, -1.97265625e-01, 3.54003906e-02, 1.09375000e-01,
1.31835938e-01, 1.66992188e-01, 2.35351562e-01, 1.04980469e-01,
-4.96093750e-01, -1.64062500e-01, -1.56250000e-01, -5.22460938e-02,
1.03027344e-01, 2.43164062e-01, -1.88476562e-01, 5.07812500e-02,
-9.37500000e-02, -6.68945312e-02, 2.27050781e-02, 7.61718750e-02,
2.89062500e-01, 3.10546875e-01, -5.37109375e-02, 2.28515625e-01,
2.51464844e-02, 6.78710938e-02, -1.21093750e-01, -2.15820312e-01,
-2.73437500e-01, -3.07617188e-02, -3.37890625e-01, 1.53320312e-01,
2.33398438e-01, -2.08007812e-01, 3.73046875e-01, 8.20312500e-02,
2.51953125e-01, -7.61718750e-02, -4.66308594e-02, -2.23388672e-02,
2.99072266e-02, -5.93261719e-02, -4.66918945e-03, -2.44140625e-01,
-2.09960938e-01, -2.87109375e-01, -4.54101562e-02, -1.77734375e-01,
-2.79296875e-01, -8.59375000e-02, 9.13085938e-02, 2.51953125e-01],
dtype=float32)
学習済みモデルを読み込み、\(vec(king) - vec(man) + vec(woman)\)を計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
その他、各言語の学習済みモデルが多数公開されています。
Name |
Model |
Data |
Dim |
Tokenizer |
Dict |
|---|---|---|---|---|---|
Skip-gram |
Wikipedia |
100,200,300 |
mecab |
mecab-ipadic-NEologd |
|
CBOW |
Wikipedia |
50 |
mecab |
mecab-ipadic-NEologd |
|
Skip-gram |
NWJC |
300 |
Sudachi |
||
Skip-gram |
求人データ |
100, 200 |
mecab |
ipadic |
|
Wikipedia |
100, 200, 300 |
Ginza |
|||
CBOW |
Common Crawl, Wikipedia |
300 |
mecab |
? |
|
Skip-gram |
Wikipedia |
100, 300 |
mecab |
? |
|
Skip-gram, fastText |
Wikipedia |
300 |
mecab |
? |
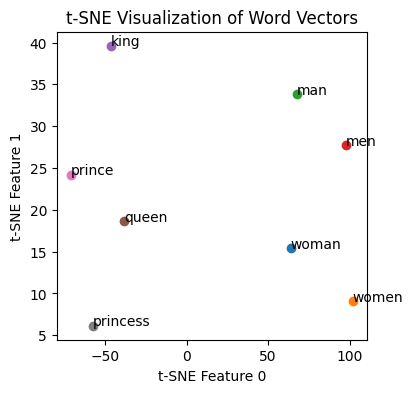
単語分散表現の可視化#
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import numpy as np
# List of words to visualize
words = ['woman', 'women', 'man', 'men', 'king', 'queen', 'prince', 'princess']
# Check if the words are in the model to avoid KeyError
vectors = [model[word] for word in words if word in model]
# Converting list of vectors to a numpy array
vectors_array = np.array(vectors)
# Applying t-SNE for dimensionality reduction
tsne = TSNE(n_components=2, random_state=0, perplexity=3)
vectors_tsne = tsne.fit_transform(vectors_array)
# Visualization
plt.figure(figsize=(4, 4))
for i, word in enumerate(words):
if word in model:
plt.scatter(vectors_tsne[i, 0], vectors_tsne[i, 1])
plt.annotate(word, (vectors_tsne[i, 0], vectors_tsne[i, 1]))
plt.xlabel('t-SNE Feature 0')
plt.ylabel('t-SNE Feature 1')
plt.title('t-SNE Visualization of Word Vectors')
plt.show()
tensorboardで単語分散表現の可視化#
可視化の際に用いられるツールとしては、TensorFlowのツールの一つであるTensorBoardが、豊富な機能とインタラクティブな操作性を備えています。
from tensorboardX import SummaryWriter
import torch
# 分散表現・単語のリストを取得
weights = model.vectors
labels = model.index_to_key
weights = weights[:1000]
labels = labels[:1000]
writer = SummaryWriter('runs/google_embeddings')
writer.add_embedding(torch.FloatTensor(weights), metadata=labels)
warning: Embedding dir exists, did you set global_step for add_embedding()?
上記スクリプトを実行すると、実行されたディレクトリにデータが作成されます。TensorBoardの起動時にrunsディレクトリを指定することで、変換した単語の分散表現が可視化できます。
tensorboard --logdir=runs
上記コマンドを実行した状態で http://localhost:6006/ にアクセスすると、PROJECTORのページにてグラフが確認できます。