BERTopic#
社会科学において、定量的な手法によってテキストの内容や構造を明らかにすることは重要な課題である。このような目的を達成するため、トピックモデルがよく用いられます。
一般的には、トピックモデルは、テキストデータを構成する各文書の背後にはトピックと呼ばれる語の集合が存在し、それに基づいて各文書が生成されるという仮定から出発します。そして、そのトピックを抽出することにより、テキストデータ全体の傾向を要約することを可能にするモデルです。また、各文書が、どのトピックから生成されているかという点についても示すことが可能となっています。 代表的なモデルとして、Latent Dirichlet allocation (LDA) が挙げられます。
このような確率的モデルに対して、文章の分散表現を使用してトピックの抽出に文章のコンテキストまで活用しようとする研究が行われています。ここでは、BERTopicという手法を解説と実装します
BERTopicの基本概念#
BERTopicのトピック抽出方法は要約すると以下の流れになリます。
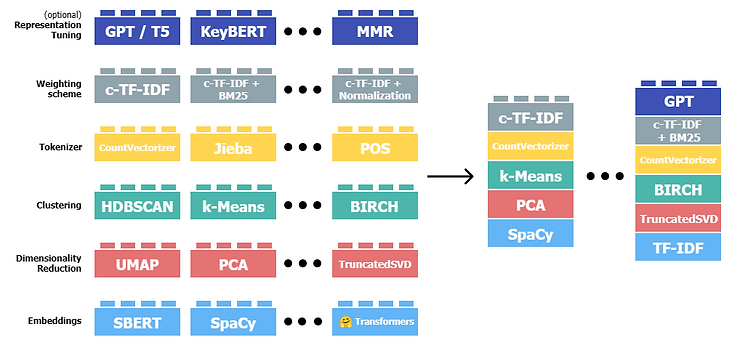
学習済みモデルで文書の埋め込みを獲得
BERTopicに使われる習済みモデルは、言語モデルの発展に伴って最先端のモデルを利用することもできます
次元削減の手法で文書の埋め込みの次元数を圧縮
埋め込みベクトルは高次元であるため、より扱いやすい低次元の空間に変換するために次元削減技術を適用します。このステップは、埋め込みベクトルの本質的な特徴を保持しつつ、計算量を減らすことができます
圧縮された文章ベクトルをクラスタリング
類似したテキストやトピックを共通のグループに分類することができます。
(c-TF-IDF による)トピックの代表単語の抽出
各クラスタに対して、それを最もよく表現する単語やフレーズを選択します。これにより、各クラスタを「トピック」として識別し、それぞれのトピックがどのような内容を含んでいるかを理解することができます。
BERTopic では、クラスタ内の単語の重要度を知るために TF-IDF を応用してその重要度を算出しています。
クラスタに含まれる文書を全て結合し 1つの文章として扱い、クラスタ単位の TF-IDF (class-based TF-IDF と呼んでいる) を以下のように計算して、それぞれの単語の重要度としています。
クラスタ\(c\)内の単語\(t\)のclass-based TF-IDF \(W_{t,c}\)は以下のようにで得られます
\[ W_{t, c} = tf_{t,c} \cdot \log \left( 1 + \frac{A}{f_t} \right) \]\(tf_{t,c}\): クラスタ\(c\)内の単語\(t\)の単語頻度
\(f_t\): 全クラスタに含まれる単語\(t\)の単語頻度
\(A\): クラスタあたりの平均単語数
#!pip install bertopic
BERTopicの実装#
サンプルデータ#
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
docs[:5]
["\n\nI am sure some bashers of Pens fans are pretty confused about the lack\nof any kind of posts about the recent Pens massacre of the Devils. Actually,\nI am bit puzzled too and a bit relieved. However, I am going to put an end\nto non-PIttsburghers' relief with a bit of praise for the Pens. Man, they\nare killing those Devils worse than I thought. Jagr just showed you why\nhe is much better than his regular season stats. He is also a lot\nfo fun to watch in the playoffs. Bowman should let JAgr have a lot of\nfun in the next couple of games since the Pens are going to beat the pulp out of Jersey anyway. I was very disappointed not to see the Islanders lose the final\nregular season game. PENS RULE!!!\n\n",
'My brother is in the market for a high-performance video card that supports\nVESA local bus with 1-2MB RAM. Does anyone have suggestions/ideas on:\n\n - Diamond Stealth Pro Local Bus\n\n - Orchid Farenheit 1280\n\n - ATI Graphics Ultra Pro\n\n - Any other high-performance VLB card\n\n\nPlease post or email. Thank you!\n\n - Matt\n',
'\n\n\n\n\tFinally you said what you dream about. Mediterranean???? That was new....\n\tThe area will be "greater" after some years, like your "holocaust" numbers......\n\n\n\n\n\t\t*****\n\tIs\'t July in USA now????? Here in Sweden it\'s April and still cold.\n\tOr have you changed your calendar???\n\n\n\t\t\t\t\t\t ****************\n\t\t\t\t\t\t ******************\n\t\t\t ***************\n\n\n\tNOTHING OF THE MENTIONED IS TRUE, BUT LET SAY IT\'s TRUE.\n\t\n\tSHALL THE AZERI WOMEN AND CHILDREN GOING TO PAY THE PRICE WITH\n\t\t\t\t\t\t **************\n\tBEING RAPED, KILLED AND TORTURED BY THE ARMENIANS??????????\n\t\n\tHAVE YOU HEARDED SOMETHING CALLED: "GENEVA CONVENTION"???????\n\tYOU FACIST!!!!!\n\n\n\n\tOhhh i forgot, this is how Armenians fight, nobody has forgot\n\tyou killings, rapings and torture against the Kurds and Turks once\n\tupon a time!\n \n \n\n\nOhhhh so swedish RedCross workers do lie they too? What ever you say\n"regional killer", if you don\'t like the person then shoot him that\'s your policy.....l\n\n\n\t\t\t\t\t\t\t\t\t\ti\n\t\t\t\t\t\t\t\t\t\ti\n\t\t\t\t\t\t\t\t\t\ti\n\tConfused?????\t\t\t\t\t\t\t\ti\n\t\t\t\t\t\t\t\t\t\ti\n Search Turkish planes? You don\'t know what you are talking about.\ti\n Turkey\'s government has announced that it\'s giving weapons <-----------i\n to Azerbadjan since Armenia started to attack Azerbadjan\t\t\n it self, not the Karabag province. So why search a plane for weapons\t\n since it\'s content is announced to be weapons? \n\n\tIf there is one that\'s confused then that\'s you! We have the right (and we do)\n\tto give weapons to the Azeris, since Armenians started the fight in Azerbadjan!\n \n\n\n\tShoot down with what? Armenian bread and butter? Or the arms and personel \n\tof the Russian army?\n\n\n',
"\nThink!\n\nIt's the SCSI card doing the DMA transfers NOT the disks...\n\nThe SCSI card can do DMA transfers containing data from any of the SCSI devices\nit is attached when it wants to.\n\nAn important feature of SCSI is the ability to detach a device. This frees the\nSCSI bus for other devices. This is typically used in a multi-tasking OS to\nstart transfers on several devices. While each device is seeking the data the\nbus is free for other commands and data transfers. When the devices are\nready to transfer the data they can aquire the bus and send the data.\n\nOn an IDE bus when you start a transfer the bus is busy until the disk has seeked\nthe data and transfered it. This is typically a 10-20ms second lock out for other\nprocesses wanting the bus irrespective of transfer time.\n",
'1) I have an old Jasmine drive which I cannot use with my new system.\n My understanding is that I have to upsate the driver with a more modern\none in order to gain compatability with system 7.0.1. does anyone know\nof an inexpensive program to do this? ( I have seen formatters for <$20\nbuit have no idea if they will work)\n \n2) I have another ancient device, this one a tape drive for which\nthe back utility freezes the system if I try to use it. THe drive is a\njasmine direct tape (bought used for $150 w/ 6 tapes, techmar\nmechanism). Essentially I have the same question as above, anyone know\nof an inexpensive beckup utility I can use with system 7.0.1']
モデルの学習#
languageで学習済みモデルの対応言語を選定します。englishの場合、all-MiniLM-L6-v2が使われます。multilingual、paraphrase-multilingual-MiniLM-L12-v2が使われます。
ドキュメント集合(
docs)を使ってトピックモデルを訓練し、ドキュメントごとのトピックとその確率を取得します。
from bertopic import BERTopic
topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(docs)
Show code cell output
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[4], line 1
----> 1 from bertopic import BERTopic
3 topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
4 topics, probs = topic_model.fit_transform(docs)
ModuleNotFoundError: No module named 'bertopic'
トピックの抽出#
freq = topic_model.get_topic_info(); freq.head(5)
| Topic | Count | Name | Representation | Representative_Docs | |
|---|---|---|---|---|---|
| 0 | -1 | 7033 | -1_to_the_of_is | [to, the, of, is, and, you, in, it, for, that] | [\n\n\tWhy do we follow God so blindly? Have ... |
| 1 | 0 | 1827 | 0_game_team_games_he | [game, team, games, he, players, season, hocke... | [1992-93 Los Angeles Kings notes and game repo... |
| 2 | 1 | 611 | 1_key_clipper_chip_encryption | [key, clipper, chip, encryption, keys, escrow,... | [From Denning:\n\n the Skipjack encryption a... |
| 3 | 2 | 532 | 2_ites_hello_cheek_hi | [ites, hello, cheek, hi, yep, huh, ken, luck, ... | [\nHuh?, Hello,, \nYep.\n] |
| 4 | 3 | 223 | 3_post_you_ted_your | [post, you, ted, your, frank, posts, me, someo... | [ (Eric Roush) writes...\n\n\n\n\nFunny. ... |
Topic:トピックのID。-1は、特定のトピックに分類されなかったドキュメントを表します。Count:そのトピックに分類されたドキュメントの数。Name:トピックの名前。これは、そのトピックの主要な単語から生成されます。Representation:そのトピックを表現する主要な単語のリスト。Representative_Docs:そのトピックに関連する代表的なドキュメントの一部。
topic_model.get_topic(0) # Select the most frequent topic
[('game', 0.010077666844196025),
('team', 0.008808261199589017),
('games', 0.007026759566637765),
('he', 0.006667539337309324),
('players', 0.0061828528854519045),
('season', 0.006127451163563256),
('hockey', 0.0059961396622373745),
('play', 0.005645631009348666),
('25', 0.0055030507175680785),
('year', 0.005457291007339096)]
トピックには、様々な属性を呼び出すメソッドが実装されています。
Attribute |
Description |
|---|---|
topics_ |
The topics that are generated for each document after training or updating the topic model. |
probabilities_ |
The probabilities that are generated for each document if HDBSCAN is used. |
topic_sizes_ |
The size of each topic |
topic_mapper_ |
A class for tracking topics and their mappings anytime they are merged/reduced. |
topic_representations_ |
The top n terms per topic and their respective c-TF-IDF values. |
c_tf_idf_ |
The topic-term matrix as calculated through c-TF-IDF. |
topic_labels_ |
The default labels for each topic. |
custom_labels_ |
Custom labels for each topic as generated through |
topic_embeddings_ |
The embeddings for each topic if |
representative_docs_ |
The representative documents for each topic if HDBSCAN is used. |
トピックモデルの可視化#
visualize_topicsメソッドを呼び出すと、各トピックが2次元空間上にプロットされ、類似のトピックが互いに近くに配置されます。これにより、トピック間の関係と各トピックの重要性(サイズによって示される)を視覚的に理解することができます。
#!pip install --upgrade nbformat
topic_model.visualize_topics()
トピックの階層関係を確認することができます。
topic_model.visualize_hierarchy(top_n_topics=50)
特定のトピック内での用語のc-TF-IDFスコアを表します。スコアが高いほど、その用語はそのトピックにとってより関連性が高い、または特徴的であることを示します。
異なるトピックのバーチャートを比較することで、トピックがその主要用語でどのように異なるかを見ることができます。
topic_model.visualize_barchart(top_n_topics=5)
Topic Representation#
学習されたトピックモデルの「性能」を向上させるために、追加の最適化ステップが行われます。
update_topicsメソッドで、既存のトピックモデルが指定するドキュメント集合(docs)に基づいて更新されます。ここでは、n_gram_range=(1, 2)と指定し、モデルが考慮する単語の組み合わせの範囲を1から2に設定することを意味します。つまり、単語単体(1-gram)と単語のペア(2-gram)が考慮されます。
topic_model.update_topics(docs, n_gram_range=(1, 2))
topic_model.get_topic(0) # We select topic that we viewed before
[('game', 0.0064307001546800675),
('team', 0.005512028783019905),
('he', 0.005048484095636265),
('games', 0.004351974525947685),
('players', 0.003733426054122323),
('the', 0.0037171364339312015),
('season', 0.0036984104773878893),
('hockey', 0.003608863894810464),
('was', 0.0035937741065264566),
('year', 0.0035436044309828394)]
reduce_topicsでトピックモデルのトピック数を減らします。トピックモデルが生成するトピックの数を制御するための方法で、トピックの数が多すぎて解釈が難しい場合や、トピック間の区別が不明瞭な場合に有用です。
topic_model.reduce_topics(docs, nr_topics=60)
2024-01-16 21:20:31,936 - BERTopic - Topic reduction - Reducing number of topics
2024-01-16 21:20:37,955 - BERTopic - Topic reduction - Reduced number of topics from 237 to 60
<bertopic._bertopic.BERTopic at 0x7f66726127d0>
find_topicsメソッドで、指定したキーワードに最も関連性の高いトピックを検索します。このメソッドを呼び出すと、指定したキーワードに最も関連性の高いトピックのIDとその関連性のスコアが返されます。
similar_topics, similarity = topic_model.find_topics("vehicle", top_n=5); similar_topics
[3, 1, 43, 20, 6]
topic_model.get_topic(3)
[('the', 0.013733097345661648),
('car', 0.012694790109122688),
('and', 0.010453824640276773),
('to', 0.010110068847887932),
('it', 0.009966543368548436),
('bike', 0.009288401924184368),
('in', 0.008568720773439823),
('you', 0.008551028342837299),
('on', 0.008478084224722732),
('is', 0.008449691655702923)]