ニューラルネットワーク#
ニューラルネットワークは、人間の脳に似た層状構造で相互接続されたノードやニューロンを使用するの計算モデルです。
ニューラルネットワークは、画像認識、自然言語処理、音声認識など、さまざまな領域で広く利用されています。特に、大量のデータと計算能力が利用可能になった近年、ディープニューラルネットワーク(DNN)の研究や応用が急速に進展しています。
ニューラルネットワークの構造#
パーセプトロン#
パーセプトロンとは、複数の入力を受け取り、重み付けして、1つの信号を出力するアルゴリズムです。
例えば,\(x_1\)と\(x_2\)の2つの入力を受け取り、yを出力するパーセプトロンを考えます。
\(w_1\)や\(w_2\)は各入力の「重み」を表すパラメータで、各入力の重要性をコントロールします。
\(b\)はバイアス
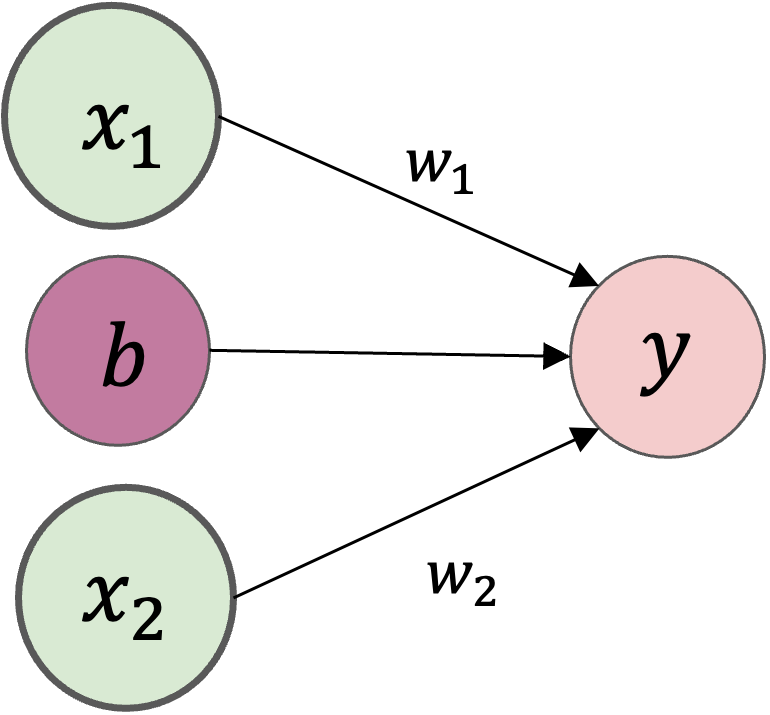
Fig. 1 パーセプトロン#
パーセプトロンの「○」で表されている部分は、ニューロンやノードと呼びます。
活性化関数#
活性化関数とは、ニューロンにおける、入力のなんらかの合計から、出力を決定するための関数です。
例えば、関数の入力(パーセプトロンだと重み付き和)が0以下のとき0を、0より大きいとき1を出力することが考えます。
出力に関する計算数式を分解すると、
で書けます。つまり、入力の重み付き和の結果が\(a\)というノードになり、そして活性化関数\(h()\)によって\(y\)という出力が計算されます。
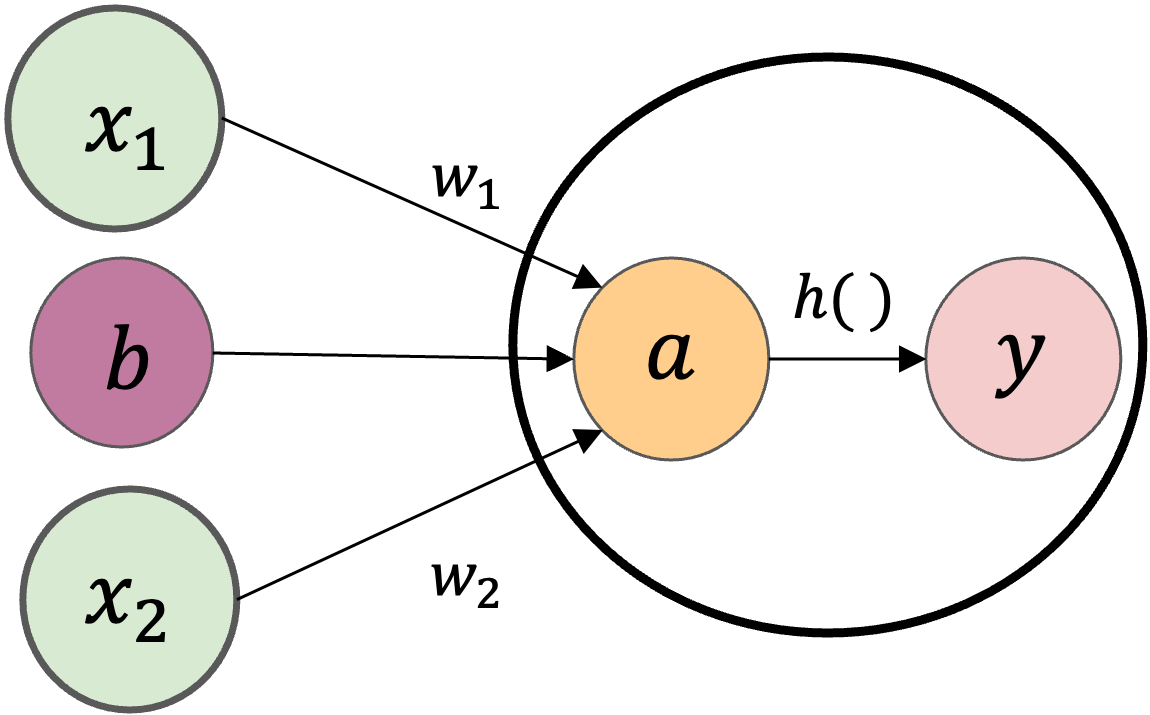
Fig. 2 活性化関数があるパーセプトロン#
活性化関数を使うことで表現の自由度を上げて、複数のパーセプトロンを適当につなげることで、入出力間が非線形な関係でも表現できるようになります。
例えば、線形変換のみで下図右の丸で表される観測データから\(x\)と\(y\)の関係を近似した場合、点線のような直線が得られたとします。これでは、一部のデータについてはあまりよく当てはまっていないのが分かります。
しかし、もし図右の実線のような曲線を表現することができれば、両者の関係をより適切に表現することができます。
![]()
活性化関数にはいくつか種類があり、異なる特性や用途を持っています。
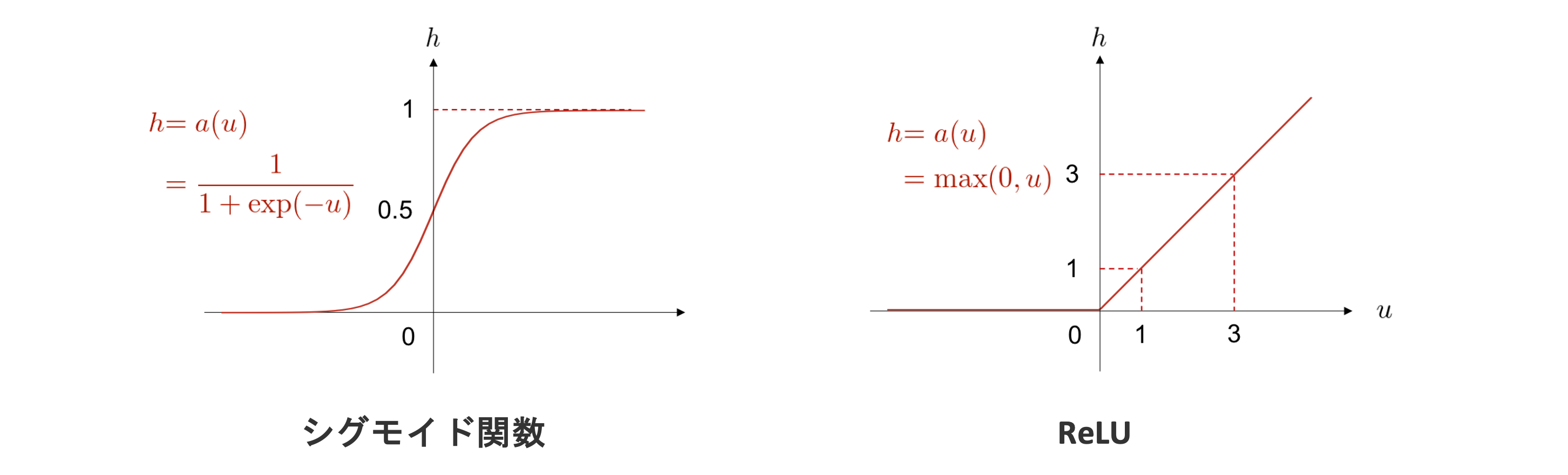
Fig. 3 活性化関数の種類#
ニューラルネットワークの仕組み#
ニューラルネットワークの仕組みは下の図で表さます。左側から、最初の層を入力層 (input layer)、最後の層を出力層 (output layer)といいます。
その間にある層は中間層 (intermediate layer) もしくは隠れ層 (hidden layer) といいます。中間層において、層の数を増やすことによって、ディープニューラルネットワークを実現することができます。
ニューラルネットワークは、層から層へ、値を変換していきます。 そのため、ニューラルネットワークとはこの変換がいくつも連なってできる一つの大きな関数だと考えることができます。 従って、基本的には、入力を受け取って、何か出力を返すものです。 そして、どのようなデータを入力し、どのような出力を作りたいかによって、入力層と出力層のノード数が決定されます。
ここで、層と層の間にあるノード間の結合は、一つ一つが重みを持っており、上のような全結合型ニューラルネットワークの場合は、それらの重みをまとめて、一つの行列で表現します。
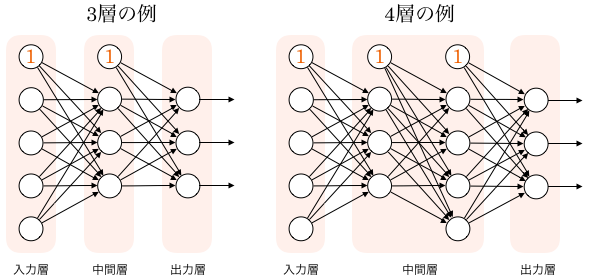
ニューラルネットワークの計算#
それでは、下図に示す\(3\)層ニューラルネットワークを例として、入力から出力への計算のについて解説を行います。
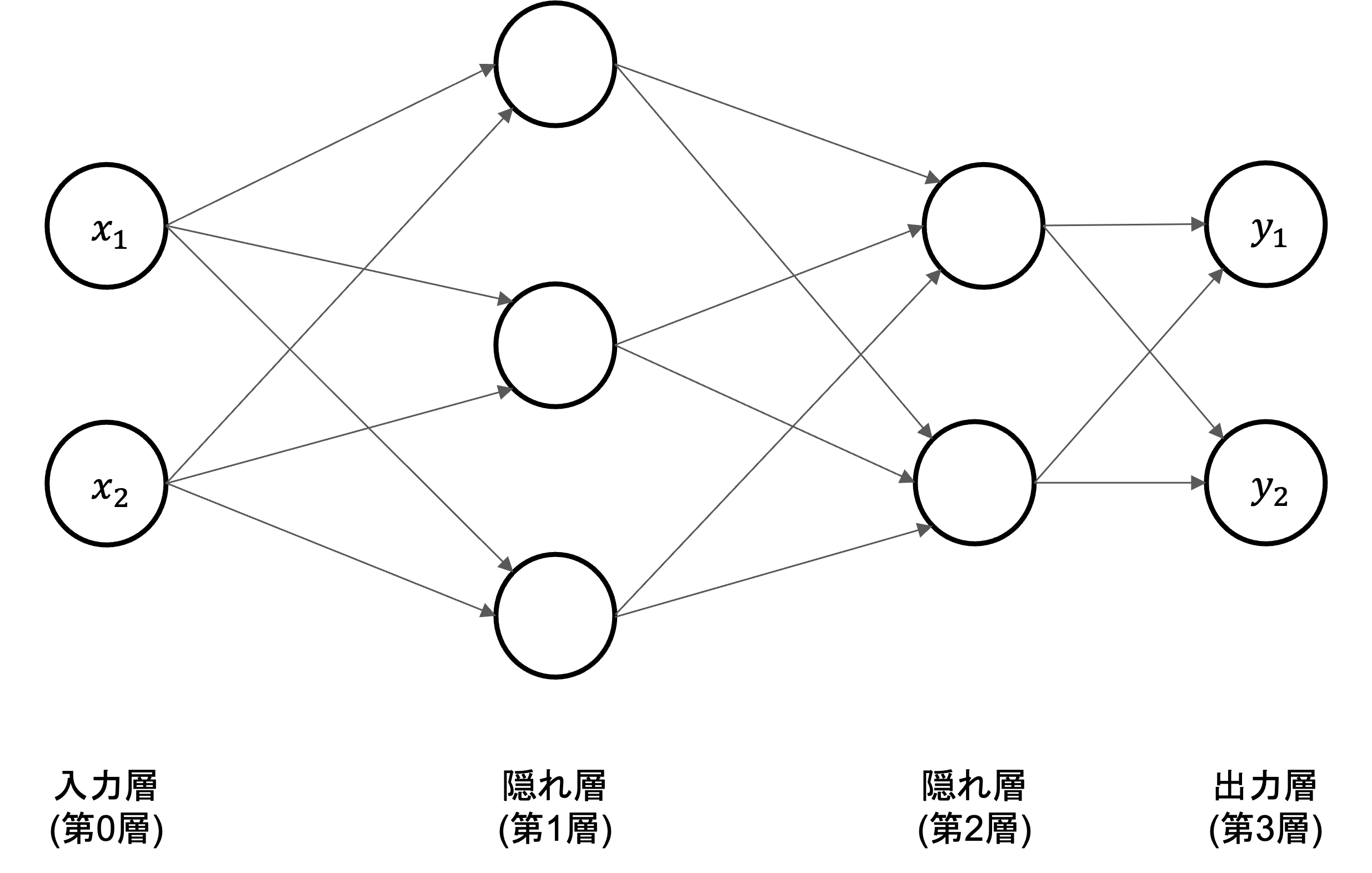
記号の説明#
ニューラルネットワークの計算を説明するにあたって、導入される記号の定義から始めます。
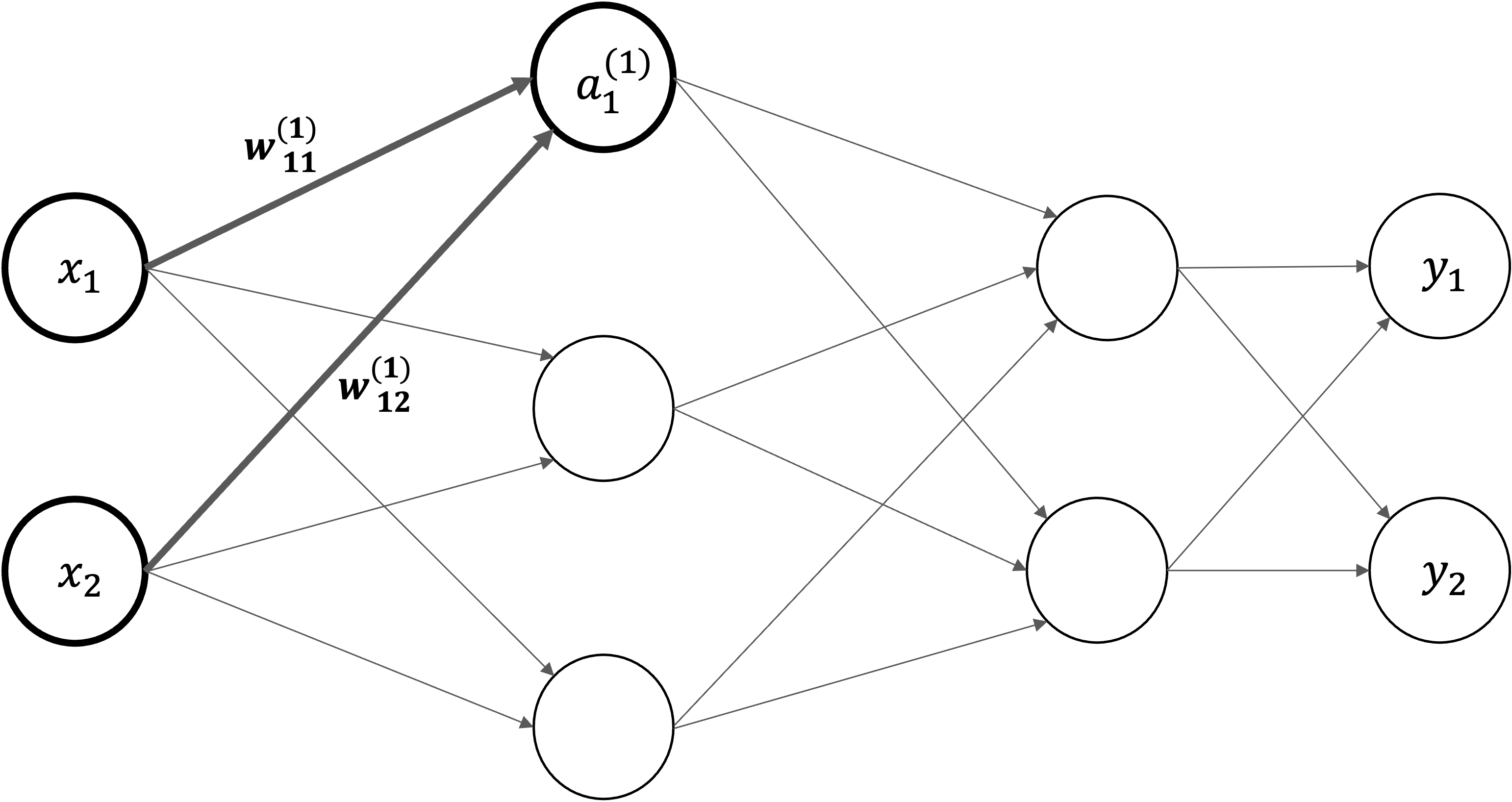
入力層の\(x_1\)と\(x_2\)ニューロンから、次層のニューロン\(a_1^{(1)}\)への信号伝達を見ていきます。
\(w_{12}^{(1)}\) は前層の\(2\)番目のニューロン(\(x_2\))から次層の\(1\)番目のニューロン(\(a_1^{(1)}\))への重みであることを意味します。
右上\((1)\)は第\(1\)層の重みということ意味します
右下\(12\)ような数字の並びは、次層のニューロン(\(1\))と前層のニューロンのインデックス番号(\(2\))から構成されます
\(a_1^{(1)}\)は第\(1\)層\(1\)番目のニューロンであることを意味します。
右上\((1)\)は第\(1\)層のニューロンということ意味します
右下\(1\)は\(1\)番目のニューロンということ意味します
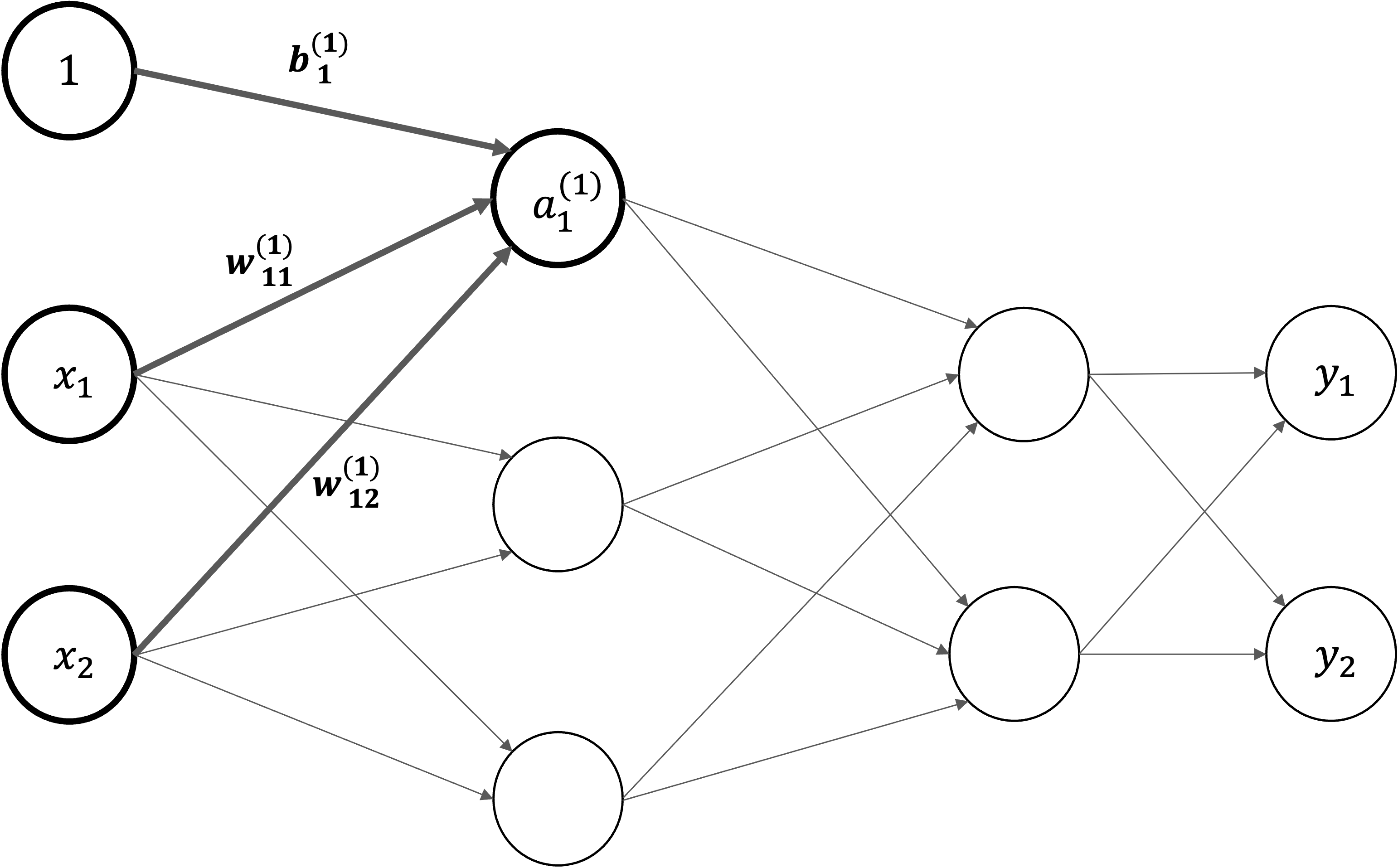
各層における信号伝達#
まず、入力層から「第\(1\)層の\(1\)番目のニューロン」への信号伝達を見ていきます。ここでは。バイアス項も追加し、\(a_1^{(1)}\)を以下の数式で計算します。
同じ形で、第\(1\)層におけるすべでのニューロンの計算式を書けます。 $\( \begin{split}\begin{cases} a_1^{(1)} = w_{11}^{(1)}x_{1} + w_{12}^{(1)}x_{1}x_{2} + b_1^{(1)} \\ a_2^{(1)} = w_{21}^{(1)}x_{1} + w_{22}^{(1)}x_{1}x_{2} + b_2^{(1)} \\ a_3^{(1)} = w_{31}^{(1)}x_{1} + w_{32}^{(1)}x_{1}x_{2} + b_3^{(1)} \end{cases}\end{split} \)$
行列で第\(1\)層におけるニューロンの計算式をまとめて表すことができます。
入力 \(\mathbf{X}=\begin{pmatrix} x_1 & x_2 \end{pmatrix}\)
バイアス \(\mathbf{B} = \begin{pmatrix} b_{1}^{(1)} & b_{2}^{(1)} & b_{3}^{(1)} \end{pmatrix}\)
重み
入力・バイアスと重みの総和: \(\mathbf{A} = \begin{pmatrix} a_1^{(1)} & a_2^{(1)} & a_3^{(1)} \end{pmatrix}\)
さらに、活性化関数を導入します。入力・バイアスと重みの総和を\(a\)で表し、活性化関数\(h()\)による変換された結果を\(z\)で表すことにします。
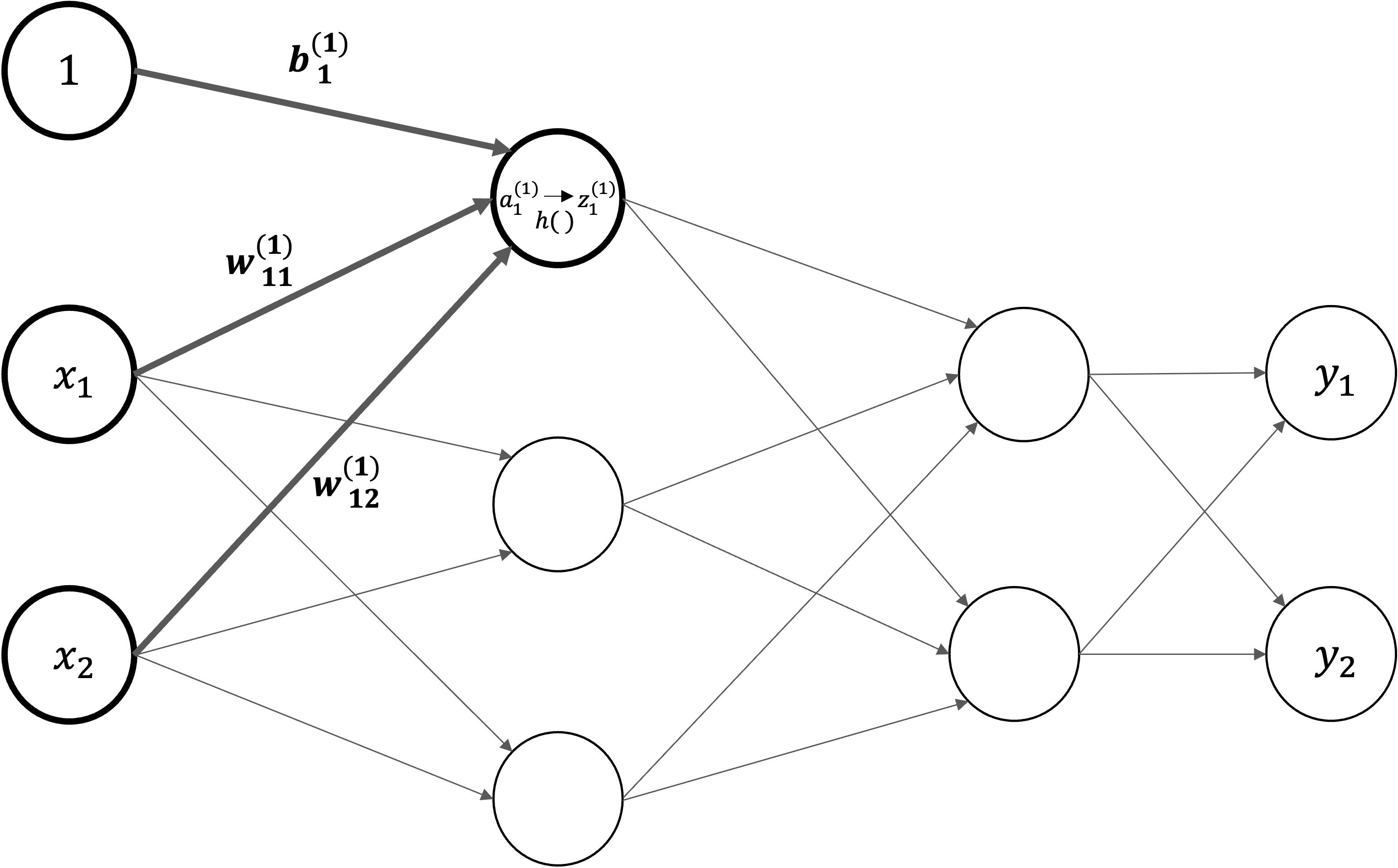
数値を見ながら計算の流れを確認#
それでは、NumPyの多次元配列を使って、入力 \(x_1\),\(x_2\),\(x_3\)から出力が計算される過程を確認してみましょう。入力、重み、バイアスは適当な値を設定します。
import numpy as np
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(r"入力の形状: {}".format(X.shape))
print(r"重みの形状: {}".format(W1.shape))
print(r"バイアスの形状: {}".format(B1.shape))
入力の形状: (2,)
重みの形状: (2, 3)
バイアスの形状: (3,)
第一層隠れ層で重み付きとバイアスの総和を計算し、活性化関数で変換された結果を返します。
A1 = np.dot(X, W1) + B1
def sigmoid(x):
return 1 / (1 + np.exp(-x))
Z1 = sigmoid(A1)
続いて、同じ形で第1層から第2層目への信号伝達を行います。
W2 = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6]])
B2 = np.array([0.1, 0.2])
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
最後に、第2層から出力層への信号を行います。出力層の活性化関数は、恒等関数を用います。
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3 # Y = A3
出力層の設計#
ニューラルネットワークは、分類問題と回帰問題の両方に用いることができます。ただし、分類問題と回帰問題のどちらに用いるかで、出力層の活性化関数を変更する必要があります。
一般的に、回帰問題では恒等関数を使います。
分類問題の場合は、クラス数と同じだけのノードを出力層に用意しておき、各ノードがあるクラスに入力が属する確率を表すようにします。 このため、全出力ノードの値の合計が\(1\)になるよう正規化します。 これには、要素ごとに適用される活性化関数ではなく、層ごとに活性値を計算する別の関数を用いる必要があります。 そのような目的に使用される代表的な関数には、ソフトマックス関数があります。
ソフトマックス関数#
ソフトマックス関数は複数値からなるベクトルを入力し、それを正規化したベクトルを出力します。ソフトマックス関数は、次の式で定義されます。
\(K\)個の要素\(\mathbf{a} = (a_0, a_1, \cdots, a_{K-1})\)を入力して、\(0 \leq y_k \leq 1\)、\(\sum_{k=0}^{K-1} y_k = 1\)となる\(\mathbf{y} = (y_0, y_1, \cdots, y_{K-1})\)を出力します。つまり、ソフトマックス関数を適用することで、各成分は区間 \((0, 1)\) に収まり、全ての成分の和が \(1\) になるため、「確率」として解釈できるようになります。
実装の際、指数関数の計算のため容易に大きな値になり、計算結果はinfが返ってきますので、数値が不安定になってしまう「オーバーフロー」問題を対応するため。入力の最大値を引くことで、正しく計算するようにする方法が採用されています。
import numpy as np
def softmax(x):
c = np.max(x)
exp_x = np.exp(x - c)
sum_exp_x = np.sum(exp_x)
return exp_x / sum_exp_x
print("活性化関数に適用する前に: {}".format(A3))
print("最終出力: {}".format(softmax(A3)))
活性化関数に適用する前に: [0.31682708 0.69627909]
最終出力: [0.40625907 0.59374093]
ニューラルネットワークの学習#
重回帰分析では、最小二乗法などの推定方法で行列計算や微分方程式を用いて解を導出することができます。つまり、実際の数値を使うことなく変数のまま、解(最適なパラメータ)を求めることができました。このように、変数のままで解を求めることを解析的に解くと言い、その答えのことを解析解 (analytical solution) と呼びます。
しかし、ニューラルネットワークで表現されるような複雑な関数の場合、パラメータの数は数億二及ぶこともありますので、最適解を解析的に解くことはほとんどの場合困難です。そのため、別の方法を考える必要があります。具体的には、解析的に解く方法に対し、計算機を使って繰り返し数値計算を行って解を求めることを数値的に解くといい、求まった解は数値解 (numerical solution) と呼ばれます。
ニューラルネットワークでは、基本的に数値的な手法によって最適なパラメータを求めます。
損失関数#
損失関数(Loss function)とは、「正解値」と、モデルによる出力された「予測値」とのズレの大きさ(これを「Loss:損失」と呼ぶ)を計算するための関数です。損失関数の値は、学習アルゴリズムがモデルのパラメータを調整する際の指標となります。
平均二乗誤差#
平均二乗誤差 (mean squared error) は、回帰問題を解きたい場合によく用いられる目的関数です。 重回帰分析の解説中に紹介した二乗和誤差と似ていますが、各データ点における誤差の総和をとるだけでなく、それをデータ数で割って、誤差の平均値を計算している点が異なります。
ここで、\(N\)はサンプルサイズ、\(y_n\)は\(n\)個目のデータに対するニューラルネットワークの出力値、\(t_n\)は\(n\)個目のデータに対する望ましい正解の値です。
交差エントロピー#
交差エントロピー (cross entropy) は、分類問題を解きたい際によく用いられる目的関数です。
例として、\(K\)クラスの分類問題を考えてみましょう。 ある入力\(x\)が与えられたとき、ニューラルネットワークの出力層に\(K\)個のノードがあり、それぞれがこの入力が\(k\)番目のクラスに属する確率
を表しているとします。 これは、入力\(x\)が与えられたという条件のもとで、予測クラスを意味する\(y\)が\(k\)であるような確率、を表す条件付き確率です。
ここで、\(x\)が所属するクラスの正解が、
というベクトルで与えられているとします。 ただし、このベクトルは\(t_k (k=1,2,...,K)\) のいずれか一つだけが\(1\)であり、それ以外は\(0\)であるようなベクトルであるとします。
そして、この一つだけ値が\(1\)となっている要素は、その要素のインデックスに対応したクラスが正解であることを意味します。
以上を用いて、交差エントロピーは以下のように定義されます。
これは、\(t_k\)が \(k=1,2,...,K\) のうち正解クラスである一つの\(k\)の値でだけ\(1\)となるので、正解クラスであるような\(k\)での\(\log y_{k}\)を取り出して\(−1\)を掛けているのと同じです。 また、\(N\)個すべてのサンプルを考慮すると、交差エントロピーは、
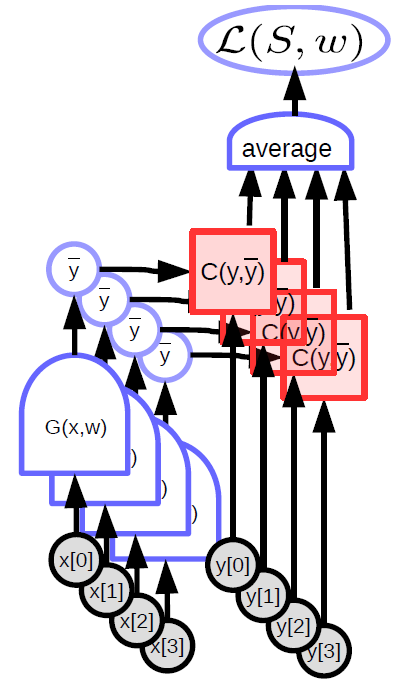
Fig. 4 Average_Loss#
3クラス分類問題を考えます。
予測は\(y=(0.1,0.2,0.3)\)、真のラベルは\(t=(0,0,1)\)の場合、交差エントロピーの計算式を書いてください。
t = np.array([0, 0, 1])
y = np.array([0.1, 0.2, 0.5])
Note
損失関数は、すべての訓練データを対象として求める必要がありますが、場合によるすべてのデータを一気に計算するのは現実ではありません。そこで、データの中から一部を選びだし、つまりミニバッチごとに学習を行います。このような手法をミニバッチ学習と言います。
損失関数の最適化#
勾配法#
下の図は,パラメータ\(w\)を変化させた際の損失関数\(L\)の値を表しています。損失関数の値を最小にするようなパラメータの値を求めることで、ニューラルネットワークを訓練します。ただ、実際のニューラルネットワークの目的関数は、多次元で、かつもっと複雑な形をしていることがほとんどです。 そこで、勾配を利用して関数の最小値を探す勾配法がよく用いられます。
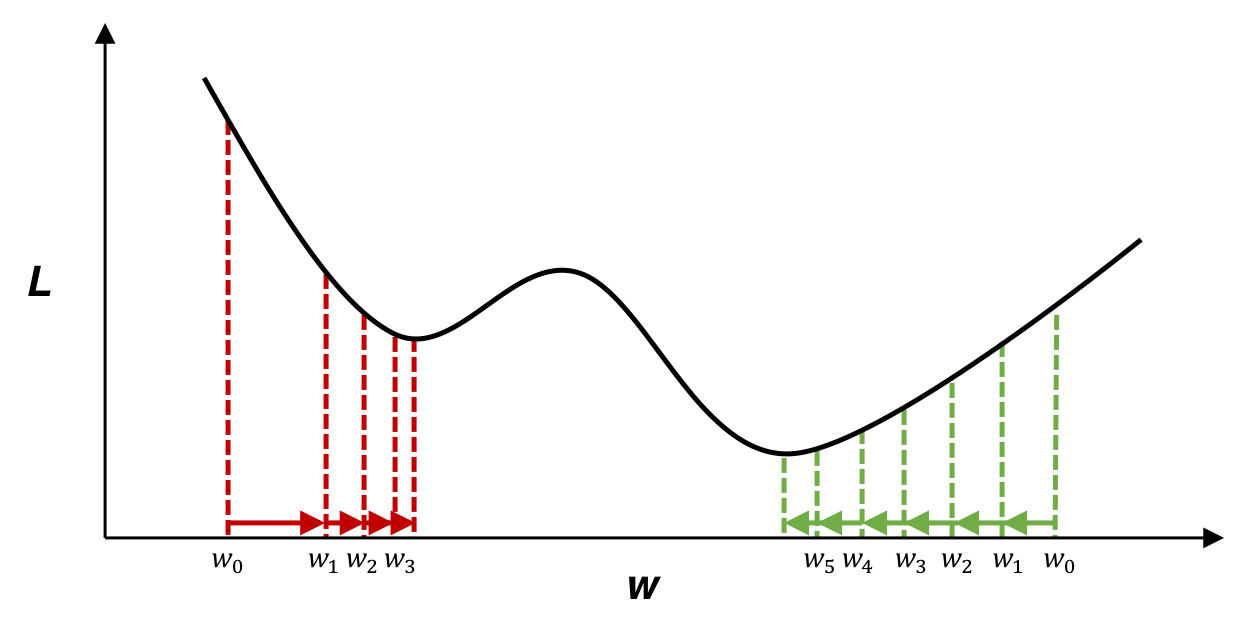
勾配は、各地点における関数の傾きであり、関数の値が最も急速に変化する方向と大きさを示します。
今は\(L\)の値を小さくしたいわけです。勾配の反対方向に進むことで関数の値を最も減らせることができますので、勾配の情報を手がかりに、できるだけ小さな値となる関数の場所を探します。
損失を求めるまでの計算を1つの関数とみなして、重みの勾配\(\frac{\partial L}{\partial \mathbf{W}}\)ととバイアスの勾配\(\frac{\partial L}{\partial \mathbf{b}}\)を求めます。各要素は、それぞれパラメータの対応する要素の偏微分です。各パラメータの勾配\(\frac{\partial L}{\partial \mathbf{W}}\)、\(\frac{\partial L}{\partial \mathbf{b}}\)を用いて、勾配降下法によりパラメータ\(\mathbf{W},\ \mathbf{b}\)を更新します。
\(\eta\)は学習率と言います。\(1\)回の学習で、どれだけパラメータを更新するか、ということを決めます。
勾配下降法の実装#
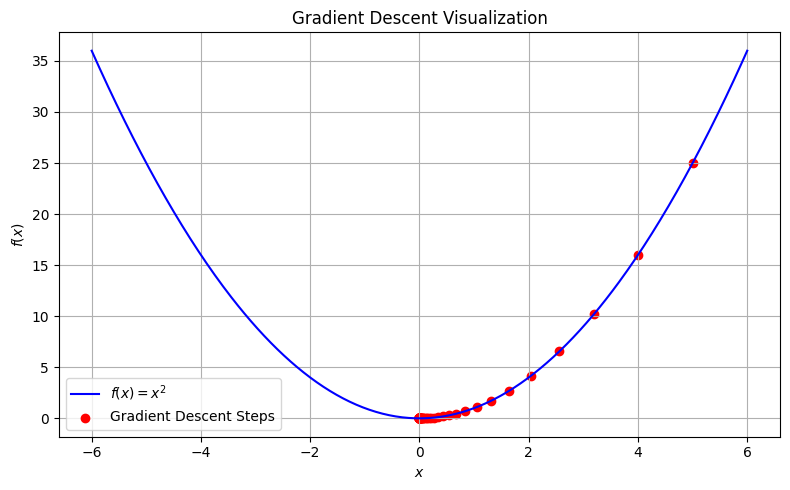
Example: \(f(x)=x^2\)に対する最適化#
import numpy as np
import matplotlib.pyplot as plt
# 関数とその勾配
def function_f(x):
return x ** 2
def numerical_gradient(f, x, h=1e-5):
return (f(x + h) - f(x - h)) / (2 * h)
def gradient_descent(initial_x, learning_rate, num_iterations):
x = initial_x
x_history = [x]
for i in range(num_iterations):
grad = numerical_gradient(function_f, x)
x = x - learning_rate * grad
x_history.append(x)
if i % 10 == 0:
print("Iteration {}: x = {}, f(x) = {}".format(i, x, function_f(x)))
return x_history
# パラメータ設定
initial_x = 5.0
learning_rate = 0.1
num_iterations = 100
x_history = gradient_descent(initial_x, learning_rate, num_iterations)
Iteration 0: x = 4.000000000037858, f(x) = 16.00000000030286
Iteration 10: x = 0.42949672960284735, f(x) = 0.18446744073954138
Iteration 20: x = 0.04611686018453473, f(x) = 0.0021267647932799246
Iteration 30: x = 0.004951760157169053, f(x) = 2.4519928654126888e-05
Iteration 40: x = 0.0005316911983169281, f(x) = 2.82695530367691e-07
Iteration 50: x = 5.708990770855627e-05, f(x) = 3.259257562171473e-09
Iteration 60: x = 6.129982163497689e-06, f(x) = 3.7576681324799807e-11
Iteration 70: x = 6.582018229321472e-07, f(x) = 4.3322963971120166e-13
Iteration 80: x = 7.067388259152886e-08, f(x) = 4.994797680561205e-15
Iteration 90: x = 7.588550360298902e-09, f(x) = 5.75860965707926e-17
# プロット
x = np.linspace(-initial_x-1, initial_x+1, 400)
y = function_f(x)
plt.figure(figsize=(8,5))
plt.plot(x, y, '-b', label='$f(x) = x^2$')
plt.scatter(x_history, [function_f(i) for i in x_history], c='red', label='Gradient Descent Steps')
plt.title('Gradient Descent Visualization')
plt.xlabel('$x$')
plt.ylabel('$f(x)$')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
勾配法で\(f(x)=2x^2-10x-80\)の最小値を求めます。
勾配降下法のアルゴリズムを実装する。
アルゴリズムを使って関数の最小値を求める。
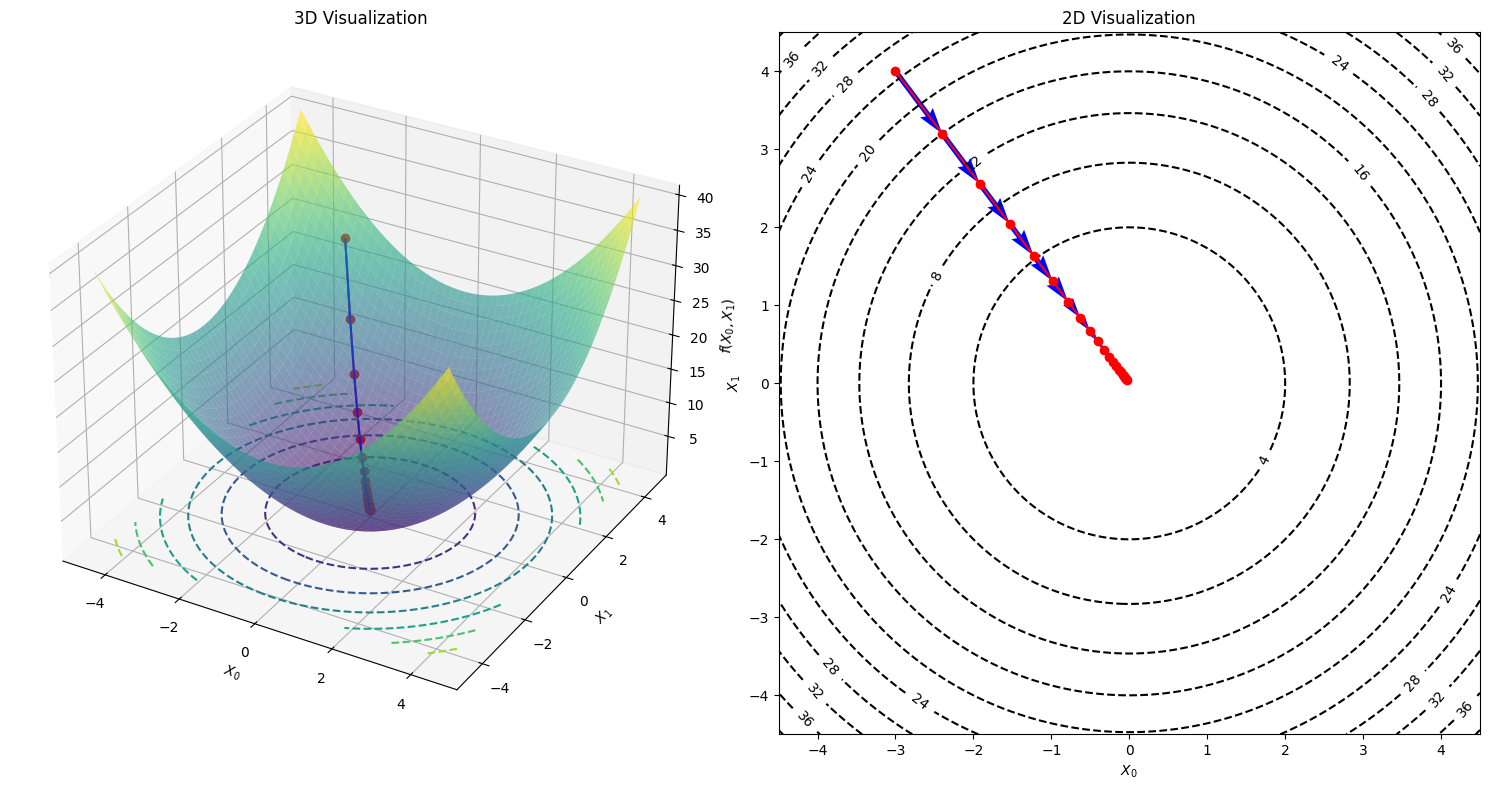
Example: \(f(x_0,x_1)=x_0^2+x_1^2\)に対する最適化#
# 関数定義
def function_f(x):
return x[0]**2 + x[1]**2
# 勾配
def numerical_gradient(f, x, h = 1e-4):
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
it.iternext()
return grad
def gradient_descent(f, init_x, lr=0.01, num_iterations=100):
x = init_x
x_history = [x.copy()]
for i in range(num_iterations):
grad = numerical_gradient(f, x)
x -= lr * grad
x_history.append(x.copy())
return np.array(x_history)
# 勾配の計算
numerical_gradient(function_f, np.array([3.0, 4.0]))
array([6., 8.])
# Parameters
init_x = np.array([-3.0, 4.0])
lr = 0.1
num_iterations = 20
# Run gradient descent
x_history = gradient_descent(function_f, init_x, lr, num_iterations)
# Generate mesh data for visualization
x = np.linspace(-4.5, 4.5, 200)
y = np.linspace(-4.5, 4.5, 200)
X, Y = np.meshgrid(x, y)
Z = X**2 + Y**2
fig = plt.figure(figsize=(15, 8))
# 1st subplot: 3D plot
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(X, Y, Z, cmap='viridis', alpha=0.6)
ax1.contour(X, Y, Z, zdir='z', offset=0, cmap='viridis', linestyles='dashed')
Z_history = np.array([function_f(x) for x in x_history])
ax1.plot(x_history[:, 0], x_history[:, 1], Z_history, 'o-', color='red')
for i in range(1, len(x_history)):
ax1.quiver(x_history[i-1][0], x_history[i-1][1], Z_history[i-1],
x_history[i][0]-x_history[i-1][0],
x_history[i][1]-x_history[i-1][1],
Z_history[i]-Z_history[i-1],
color="blue", arrow_length_ratio=0.05)
ax1.set_xlabel("$X_0$")
ax1.set_ylabel("$X_1$")
ax1.set_zlabel("$f(X_0, X_1)$")
ax1.set_title("3D Visualization")
# 2nd subplot: 2D contour plot
ax2 = fig.add_subplot(122)
contour = ax2.contour(X, Y, Z, levels=10, colors='black', linestyles='dashed')
ax2.clabel(contour)
for i in range(1, len(x_history)):
ax2.quiver(x_history[i-1][0], x_history[i-1][1],
x_history[i][0]-x_history[i-1][0],
x_history[i][1]-x_history[i-1][1],
angles="xy", scale_units="xy", scale=1, color="blue")
ax2.plot(x_history[:, 0], x_history[:, 1], 'o-', color='red')
ax2.set_xlim(-4.5, 4.5)
ax2.set_ylim(-4.5, 4.5)
ax2.set_xlabel("$X_0$")
ax2.set_ylabel("$X_1$")
ax2.set_title("2D Visualization")
# Display the figure
plt.tight_layout()
plt.show()
ニューラルネットワークに対する勾配#
ニューラルネットワークにおいて、重みパラメータの勾配を求める計算を確認します。
ここで、形状が\(2 \times 3\)の重み\(\mathbf{W}\)を持つニューラルネットワークがあり、損失関数を\(L\)で表すことを考えましょう。この場合、勾配は\(\frac{\partial L}{\partial \mathbf{W}}\)で表すことができます。
# (仮の)入力データを作成
x = np.array([0.6, 0.9])
print(x)
# (仮の)教師データを作成
t = np.array([0, 0, 1])
print(t)
[0.6 0.9]
[0 0 1]
np.random.seed(0) # 乱数のシードを固定
class simplenet:
def __init__(self):
self.W = np.random.randn(2, 3)# 重みを初期化する関数を定義
def predict(self, x):
return np.dot(x, self.W) # 重み付き和を計算
def loss(self, x, t):
z = self.predict(x)
y = softmax(z) # ソフトマックス関数による正規化
loss = cross_entropy_error(y, t) # 交差エントロピー誤差を計算
return loss
net = simplenet()
p = net.predict(x)
print(p)
[ 3.07523529 1.92089652 -0.2923073 ]
net.loss(x, t)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[22], line 1
----> 1 net.loss(x, t)
Cell In[20], line 10, in simplenet.loss(self, x, t)
8 z = self.predict(x)
9 y = softmax(z) # ソフトマックス関数による正規化
---> 10 loss = cross_entropy_error(y, t) # 交差エントロピー誤差を計算
11 return loss
NameError: name 'cross_entropy_error' is not defined
続いて、勾配を求めてみましょう。
# 損失メソッドを実行する関数を作成
def f(W):
# 損失メソッドを実行
return net.loss(x, t)
# 損失を計算
L = f(net.W)
print(L)
3.6674507891066104
# 重みの勾配を計算
dW = numerical_gradient(f, net.W)
print(dW)
[[ 0.44452826 0.14014461 -0.58467287]
[ 0.66679239 0.21021692 -0.87700931]]
これで重みの勾配\(\frac{\partial L}{\partial \mathbf{W}}\)を得られました。
その中身を見ると、例えば、\(\frac{\partial L}{\partial \mathbf{W_{1,1}}}\)はおよそ\(0.44\)ということは、\(w_{1,1}\)を\(h\)だけ増やすと損失関数の値は\(0.44h\)だけ増加することを意味します。
そのため、損失関数の値を減らすために、\(w_{1,1}\)はマイナス方向へ更新するのが良いことがわかりました。
パラメータの勾配が得られたということは、パラメータの学習を行えるようになったということです。
2層ニューラルネットワークの実装#
これまでに勉強した、「損失関数」、「ミニバッチ」、「勾配」、「勾配下降法」をまとめて、ニューラルネットワークの学習手順を確認します。
ミニバッチ: データセットからミニバッチをランダムに取り出す。ここでは、そのミニバッチの損失関数の値を減らすkとを目的とする。
勾配の算出:各重みパラメータの勾配を求める。
パラメーターの更新:重みパラメータを勾配方向に微少量だけ更新する。
収束するまで繰り返す
ここでは、2層のニューラルネットワークをクラスとして実装します。
実装するクラスは、「パラメータの初期化」「2層のニューラルネットワークの計算(推論処理)」「損失の計算」「認識精度の計算」「勾配の計算」の機能(メソッド)を持ちます。
数式の確認#
入力層#
ニューラルネットワークの入力\(\mathbf{X}\)、第\(1\)層の重み\(\mathbf{W^{(1)}}\)と\(\mathbf{b}^{(1)}\)を次の形状とします。
ここで、\(\mathbf{N}\)はバッチサイズ、\(\mathbf{D}\)は各データ\(\mathbf{x}_n = (x_{n,0}, \cdots, x_{n,D-1})\)の要素数、、\(\mathbf{H}\)は中間層のニューロン数です。
隠れ層#
第\(1\)層の重み付き和\(\mathbf{A}^{(1)}\)を計算します。
\(\mathbf{N} \times \mathbf{D}\)と\(\mathbf{D} \times \mathbf{H}\)の行列の積なので、計算結果は\(\mathbf{N} \times \mathbf{H}\)の行列になります。
重み付き和\(\mathbf{A}^{(1)}\)の各要素をシグモイド関数により活性化します。
ただ、活性化関数は形状(\(\mathbf{N} \times \mathbf{H}\))に影響しません。第1層の出力の結果は、
になります。
出力層#
次に、第\(2\)層の重み\(\mathbf{W^{(2)}}\)と\(\mathbf{b}^{(2)}\)は以下のように形状しています。
ここで、\(\mathbf{H}\)は中間層のニューロン数、\(\mathbf{K}\)は出力層のクラス数です。
第2層の重み付き和\(\mathbf{A}^{(2)}\)は
\(\mathbf{N} \times \mathbf{H}\)と\(\mathbf{H} \times \mathbf{K}\)の行列の積なので、計算結果は\(\mathbf{N} \times \mathbf{K}\)の行列になります。
ここで、ソフトマックス関数により各データの重み付き和\(a_{n}^{(2)}\)を活性化して、ニューラルネットワークの出力\(y_n\)とします。
\(\mathbf{Y}\)でニューラルネットワークの出力を表します。\(n\)番目のデータに関する出力\(\mathbf{y}_n\)は、\(0 \leq y_{n,k} \leq 1\)、\(\sum_{k=0}^{K-1} y_{n,k} = 1\)に正規化されており、\(n\)番目の入力データ\(\mathbf{x}_n\)がどのクラスのかを表す確率分布として扱えるのでした。
損失の計算#
\(N\)個のデータに関する教師データ\(\mathbf{T}\)は、出力\(\mathbf{Y}\)と同じ形状になります。
特に、分類問題の場合、各データの教師データ\(t_n\)は、、正解ラベルが\(1\)でそれ以外が\(0\)といった形になります。
(平均)交差エントロピー誤差を計算して、損失\(L\)とします。
勾配の計算#
損失を求めるまでの計算を1つの関数とみなして、重みの勾配\(\frac{\partial L}{\partial \mathbf{W}}\)とバイアスの勾配\(\frac{\partial L}{\partial \mathbf{b}}\)を求めます。
第\(1\)層のパラメータ\(\mathbf{W}^{(1)},\ \mathbf{b}^{(1)}\)を\(\frac{\partial L}{\partial \mathbf{W}^{(1)}},\ \frac{\partial L}{\partial \mathbf{b}^{(1)}}\)で表します。
同様に、第\(1\)層のパラメータ\(\mathbf{W}^{(2)},\ \mathbf{b}^{(2)}\)を\(\frac{\partial L}{\partial \mathbf{W}^{(2)}},\ \frac{\partial L}{\partial \mathbf{b}^{(2)}}\)で表します。
各要素は、それぞれパラメータの対応する要素の偏微分です。
パラメータの更新#
各パラメータの勾配、\(\frac{\partial L}{\partial \mathbf{W}},\ \frac{\partial L}{\partial \mathbf{b}}\)を用いて、勾配降下法によりパラメータ\(\mathbf{W},\ \mathbf{b}\)を更新します。
更新後のパラメータを\(\mathbf{W}^{(\mathrm{new})},\ \mathbf{b}^{(\mathrm{new})}\)とすると、更新式は次の式で表せます。
各要素に注目すると、それぞれ次の計算をしています。
2層ニューラルネットワークのクラス#
class TwoLayerNet:
# 初期化メソッド
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# ディクショナリを初期化
self.params = {}
# パラメータの初期値をディクショナリに格納
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) # 第1層の重み
self.params['b1'] = np.zeros(hidden_size) # 第1層のバイアス
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size) # 第2層の重み
self.params['b2'] = np.zeros(output_size) # 第2層のバイアス
# 推論メソッド
def predict(self, x):
# パラメータを取得
W1, W2 = self.params['W1'], self.params['W2'] # 重み
b1, b2 = self.params['b1'], self.params['b2'] # バイアス
# 第1層の計算
a1 = np.dot(x, W1) + b1 # 重み付き和
z1 = sigmoid(a1) # 活性化
# 第2層の計算
a2 = np.dot(z1, W2) + b2 # 重み付き和
y = softmax(a2) # 活性化(正規化)
return y
# 損失メソッド
def loss(self, x, t):
# ニューラルネットワークの計算
y = self.predict(x)
# 交差エントロピー誤差を計算
return cross_entropy_error(y, t)
# 認識精度メソッド
def accuracy(self, x, t):
# ニューラルネットワークの計算
y = self.predict(x)
# ラベルを抽出
y = np.argmax(y, axis=1) # 予測結果
t = np.argmax(t, axis=1) # 正解ラベル
# 精度を計算
accuracy = np.sum(y == t) / float(x.shape[0]) # 正解率
return accuracy
# 勾配メソッド
def numerical_gradient(self, x, t):
# 損失を求める関数を作成
loss_W = lambda W: self.loss(x, t)
# ディクショナリを初期化
grads = {}
# 各パラメータの勾配を計算してディクショナリに格納
grads['W1'] = numerical_gradient(loss_W, self.params['W1']) # 第1層の重みの勾配
grads['b1'] = numerical_gradient(loss_W, self.params['b1']) # 第1層のバイアスの勾配
grads['W2'] = numerical_gradient(loss_W, self.params['W2']) # 第2層の重みの勾配
grads['b2'] = numerical_gradient(loss_W, self.params['b2']) # 第2層のバイアスの勾配
return grads
2層ニューラルネットワークのクラスの定義は少し複雑に見えるようですが、これまで説明した実装と共通する部分が多いです。
ニューラルネットワークに対する理解を深めるために、実装コードを確認しながらもう一回ニューラルネットワークの計算の流れを確認しましょう。
入力データの用意#
# バッチサイズ(1試行当たりのデータ数)を指定
batch_size = 100
# 入力データの要素数を指定:(固定)
input_size = 784
# 中間層のニューロン数を指定
hidden_size = 50
# クラス数を指定:(固定)
output_size = 10
# (仮の)入力データを作成
x = np.random.rand(batch_size, input_size)
print(x[:5, :5])
print(x.shape)
# (仮の)教師データ(正解ラベル)を作成
#t = np.random.rand(batch_size, output_size)
t = np.random.multinomial(n=1, pvals=np.repeat(1 / output_size, output_size), size=batch_size)
print(t[:5, :])
print(t.shape)
[[0.92134902 0.8952732 0.75852961 0.67511765 0.7200242 ]
[0.17875607 0.06307972 0.16808422 0.3823676 0.78191228]
[0.34858203 0.53831853 0.45071805 0.35453929 0.87776074]
[0.56680049 0.55845259 0.20077398 0.47377395 0.68237887]
[0.3681299 0.66866691 0.22150919 0.56623481 0.29869918]]
(100, 784)
[[0 0 1 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 0 0 0 1]]
(100, 10)
パラメータの初期化#
重みの初期値の標準偏差をweight_init_stdとして指定して、各層のパラメータ(重みとバイアス)\(\mathbf{W},\ \mathbf{b}\)を作成します。
# 重みの初期値の標準偏差を指定
weight_init_std = 0.01
# 第1層の重みを初期化
W1 = weight_init_std * np.random.randn(input_size, hidden_size) # 重みは正規分布に従う乱数で初期化します
print("第1層の重み")
print(W1[:5, :5])
print(W1.shape)
# 第1層のバイアスを初期化
b1 = np.zeros(hidden_size) # バイアスは全ての要素が0の配列で作成します
print("第1層のバイアス")
print(b1[:5])
print(b1.shape)
# 第2層の重みを初期化
W2 = weight_init_std * np.random.randn(hidden_size, output_size) # 重みは正規分布に従う乱数で初期化します
print("第2層の重み")
print(W2[:5, :5])
print(W2.shape)
# 第2層のバイアスを初期化
b2 = np.zeros(output_size) # バイアスは全ての要素が0の配列で作成します
print("第2層のバイアス")
print(b2[:5])
print(b2.shape)
第1層の重み
[[-0.00251984 0.00393282 -0.01154487 -0.02368748 0.01199835]
[ 0.00696885 0.01819666 -0.00411091 -0.00657152 0.02849638]
[ 0.00888224 0.01015954 -0.00686909 -0.00135367 0.00396966]
[ 0.00139235 -0.00608655 0.01256677 0.00828721 -0.00458018]
[-0.00790946 0.01154107 0.0037062 -0.00984002 -0.00270123]]
(784, 50)
第1層のバイアス
[0. 0. 0. 0. 0.]
(50,)
第2層の重み
[[ 0.00154326 -0.01220577 0.00673438 0.00775144 -0.00437817]
[ 0.00465035 0.00888546 0.00360615 0.0031593 -0.01404784]
[ 0.00798442 -0.00743696 0.01250895 -0.0097004 0.01509636]
[-0.0124286 -0.00586066 -0.00626555 0.01271291 0.0012766 ]
[-0.00197648 -0.00331351 0.01850372 -0.00701401 0.00540954]]
(50, 10)
第2層のバイアス
[0. 0. 0. 0. 0.]
(10,)
クラス内重みの初期化を行う関数を定義しています。
パラメータの形状に関する値と標準偏差を引数に指定します。
作成した全てのパラメータを辞書型の変数
paramsに格納します。
# パラメータを初期化する関数を定偽
def init_params(input_size, hidden_size, output_size, weight_init_std=0.01):
# ディクショナリを初期化
params = {}
# パラメータの初期値をディクショナリに格納
params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) # 第1層の重み
params['b1'] = np.zeros(hidden_size) # 第1層のバイアス
params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size) # 第2層の重み
params['b2'] = np.zeros(output_size) # 第2層のバイアス
return params
params = init_params(input_size, hidden_size, output_size, weight_init_std)
print(params.keys())
dict_keys(['W1', 'b1', 'W2', 'b2'])
ニューラルネットワークの計算#
# 第1層の重み付き和を計算
a1 = np.dot(x, W1) + b1
print("第1層の重み付き和を計算")
print(a1[:5, :5])
print(a1.shape)
# 第1層の出力を計算(重み付き和を活性化)
z1 = sigmoid(a1)
print("第1層の出力を計算(重み付き和を活性化)")
print(z1[:5, :5])
print(z1.shape)
第1層の重み付き和を計算
[[-0.21125577 0.15609414 0.14604074 0.0444226 0.15940158]
[-0.29585853 0.00171761 0.24107279 0.09963502 0.19082985]
[-0.25703736 0.20220727 0.12471513 -0.0038649 0.10273432]
[-0.19100973 0.1581395 0.18751483 0.05689667 0.30455912]
[-0.32148669 0.09312981 0.24420542 0.01638803 0.23673517]]
(100, 50)
第1層の出力を計算(重み付き和を活性化)
[[0.4473816 0.53894449 0.53644543 0.51110382 0.53976623]
[0.42657021 0.5004294 0.559978 0.52488817 0.54756321]
[0.43609213 0.55038027 0.53113843 0.49903378 0.52566101]
[0.45239223 0.53945269 0.54674183 0.51422033 0.57555665]
[0.42031347 0.52326564 0.56074975 0.50409692 0.55890893]]
(100, 50)
# 第2層の重み付き和を計算
a2 = np.dot(z1, W2) + b2
print("第2層の重み付き和を計算")
print(a2[:5, :5])
print(a2.shape)
# 第2層の出力を計算(重み付き和を活性化)
y = softmax(a2)
print("第2層の出力を計算(重み付き和を活性化)")
print(y[:5, :5])
print(y.shape)
第2層の重み付き和を計算
[[-0.00291321 -0.05240607 -0.00207278 0.01565742 0.00777209]
[-0.00549181 -0.05382696 -0.0012131 0.01535286 0.00729162]
[-0.00450256 -0.05171541 -0.00110888 0.01634152 0.00673576]
[-0.00490802 -0.05190935 0.00055753 0.01508643 0.00696235]
[-0.00441093 -0.05320483 -0.00425852 0.01319074 0.00539571]]
(100, 10)
第2層の出力を計算(重み付き和を活性化)
[[0.00099442 0.0009464 0.00099525 0.00101306 0.0010051 ]
[0.00099186 0.00094506 0.00099611 0.00101275 0.00100462]
[0.00099284 0.00094705 0.00099621 0.00101375 0.00100406]
[0.00099244 0.00094687 0.00099787 0.00101248 0.00100429]
[0.00099293 0.00094564 0.00099308 0.00101056 0.00100271]]
(100, 10)
推論処理(2層のニューラルネットワークの計算)を行う関数として以下のように定義します。
入力データxと全てのパラメータを格納したparamsを引数に渡します。
# 推論を行う関数を定義
def predict(x, params):
# パラメータを取得
W1, W2 = params['W1'], params['W2'] # 重み
b1, b2 = params['b1'], params['b2'] # バイアス
# 第1層の計算
a1 = np.dot(x, W1) + b1 # 重み付き和
z1 = sigmoid(a1) # 活性化
# 第2層の計算
a2 = np.dot(z1, W2) + b2 # 重み付き和
y = softmax(a2) # 活性化(正規化)
return y
# 2層のニューラルネットワークの計算
y = predict(x, params)
print(np.round(y[:5], 4))
print(np.sum(y[:5], axis=1)) # 正規化の確認
print(np.argmax(y[:5], axis=1)) # 推論結果の抽出
[[0.001 0.001 0.0009 0.001 0.001 0.001 0.001 0.001 0.001 0.001 ]
[0.001 0.001 0.0009 0.001 0.001 0.001 0.001 0.001 0.001 0.001 ]
[0.001 0.001 0.0009 0.001 0.001 0.001 0.001 0.001 0.001 0.001 ]
[0.001 0.001 0.0009 0.001 0.001 0.001 0.001 0.001 0.001 0.001 ]
[0.001 0.001 0.0009 0.001 0.001 0.001 0.001 0.001 0.001 0.001 ]]
[0.00999795 0.00999911 0.01000043 0.01000098 0.00999859]
[1 4 1 1 1]
損失の計算#
# 損失を計算する関数を定義
def loss(x, params, t):
# ニューラルネットワークの計算
y = predict(x, params)
# 交差エントロピー誤差を計算
return cross_entropy_error(y, t)
# 損失を計算
L = loss(x, params, t)
print(L)
690.7244647105006
精度の計算#
出力\(\mathbf{Y}\)と教師データ\(\mathbf{T}\)と比較して、推論結果の精度を計算します。
np.argmax()を使って、ニューラルネットワークの出力\(y\)と教師データ\(t\)の最大値のインデックスを抽出します。
# 予測ラベルを抽出
y_label = np.argmax(y, axis=1)
print(y_label[:5])
# 正解ラベルを抽出
t_label = np.argmax(t, axis=1)
print(t_label[:5])
# 値を比較
result = y_label == t_label
print(result[:5])
# 正解数を計算
print(np.sum(result))
[1 4 1 1 1]
[2 8 5 5 9]
[False False False False False]
10
# 正解率を計算
acc = np.sum(y_label == t_label) / x.shape[0]
print(acc)
0.1
def accuracy(x, params, t):
# ニューラルネットワークの計算
y = predict(x, params)
# ラベルを抽出
y = np.argmax(y, axis=1) # 予測
t = np.argmax(t, axis=1) # 正解
# 正解率を計算
accuracy = np.sum(y == t) / float(x.shape[0]) # (正解数) / (画像数)
return accuracy
勾配の計算#
numerical_gradient()に損失を求める関数fと各パラメータを指定して、各パラメータの勾配を計算します。
# 損失メソッドを実行する関数を作成
def f(W):
return loss(x, params, t)
# 第1層の重みの勾配を計算
dW1 = numerical_gradient(f, params['W1'])
print(dW1[:5, :5])
print(dW1.shape)
# 第1層のバイアスの勾配を計算
db1 = numerical_gradient(f, params['b1'])
print(db1[:5])
print(db1.shape)
# 第2層の重みの勾配を計算
dW2 = numerical_gradient(f, params['W2'])
print(dW2[:5, :5])
print(dW2.shape)
# 第2層のバイアスの勾配を計算
db2 = numerical_gradient(f, params['b2'])
print(db2[:5])
print(db2.shape)
[[-0.0162214 0.00738879 -0.00890744 0.00464787 0.0006635 ]
[-0.00202843 0.00041813 -0.00937427 0.00499212 -0.00285974]
[-0.02189302 0.01237483 -0.01689411 0.0032458 -0.00728235]
[ 0.00228273 -0.00572283 -0.00250148 0.00370099 -0.00578303]
[ 0.008293 -0.01004806 0.00099331 0.00235795 -0.00921599]]
(784, 50)
[-0.01590313 0.00457492 -0.01767358 0.00802107 -0.00609883]
(50,)
[[ 0.8439857 -0.91240074 -0.28306074 0.54814382 0.14268576]
[ 0.99589429 -0.92808364 -0.43861511 0.54960735 0.05951215]
[ 0.91239954 -0.84740315 -0.42242193 0.56432805 0.17610717]
[ 0.96044333 -0.86093102 -0.46614506 0.51563735 0.16195769]
[ 1.03998822 -0.82552694 -0.37638349 0.51322829 0.07020229]]
(50, 10)
[ 1.82620167 -1.72817199 -0.68642318 1.13082065 0.24819032]
(10,)
勾配の計算結果を、辞書型の変数gradsに格納します。
# 勾配を計算する関数を定義
def numerical_gradient_tmp(x, W, t):
# 損失を求める関数を作成
loss_W = lambda W: loss(x, params, t)
# 各パラメータの勾配
grads = {}
# 各パラメータの勾配をディクショナリに格納
grads['W1'] = numerical_gradient(loss_W, params['W1']) # 第1層の重みの勾配
grads['b1'] = numerical_gradient(loss_W, params['b1']) # 第1層のバイアスの勾配
grads['W2'] = numerical_gradient(loss_W, params['W2']) # 第2層の重みの勾配
grads['b2'] = numerical_gradient(loss_W, params['b2']) # 第2層のバイアスの勾配
return grads
実装#
処理の確認ができたので、2層のニューラルネットワークをクラスとして実装します。
TwoLayerNetクラスのインスタンスを作成します。
# インスタンスを作成
net = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
net.params.keys()
dict_keys(['W1', 'b1', 'W2', 'b2'])
# ニューラルネットワークの計算
y = net.predict(x)
print(np.round(y[:5], 4)) # 値の確認
print(np.sum(y[:5], axis=1)) # 正規化の確認
print(np.argmax(y[:5], axis=1)) # 推論結果の確認
[[0.001 0.001 0.001 0.001 0.001 0.001 0.001 0.0011 0.001 0.001 ]
[0.001 0.001 0.001 0.001 0.001 0.001 0.001 0.0011 0.001 0.001 ]
[0.001 0.001 0.001 0.001 0.001 0.001 0.001 0.0011 0.001 0.001 ]
[0.001 0.001 0.001 0.001 0.001 0.001 0.001 0.0011 0.001 0.001 ]
[0.001 0.001 0.001 0.001 0.001 0.001 0.001 0.0011 0.0009 0.001 ]]
[0.00999732 0.00999924 0.0100035 0.01000184 0.01000093]
[7 7 7 7 7]
# 損失を計算
L = net.loss(x, t)
print(L)
691.1148764693589
# 認識精度を計算
acc = net.accuracy(x, t)
print(acc)
0.08
# 各パラメータの勾配を計算
grads = net.numerical_gradient(x, t)
print(grads.keys())
dict_keys(['W1', 'b1', 'W2', 'b2'])