誤差逆伝播法#
これまでは、ニューラルネットワークの各パラメータについての目的関数の数値微分を計算することで勾配の計算を求める方法を説明しました。
勾配ベクトルの各成分は、各層の結合重みと各ユニットのバイアスでの損失関数の微分です。
しかし、ニューラルネットワークの層数が多くなると、数値微分の計算は膨大な時間がかかるでしょう。さらに、特に入力に近い深い層のパラメータほど、計算の手間が多くなります。
ここで、パラメータの勾配の計算を効率よく行う手法である「誤差逆伝播法」について学びます。
連鎖律#
複数の関数によって構成される関数を合成関数と呼びます。
合成関数の微分は、「\(t\)に関する\(z\)の微分\(\frac{\partial z}{\partial t}\)」と「\(x\)に関する\(t\)の微分\(\frac{\partial t}{\partial 1}\)」の積のように、それぞれの関数の微分の積で求められます。
線形変換の逆伝播の導出#
入力データ\(\mathbf{x}\)は\((N \times D)\)の行列、\(\mathbf{W}\)は\((D \times H)\)の行列、\(\mathbf{b}\)は要素数\(H\)のベクトルと考え、線形変換の計算は以下の式で表します。
ここで、「\(n\)番目の出力データの\(h\)番目の項\(y_{n,h}\)」は、
で計算できるのが分かります。
重みの勾配#
例えば、損失関数に二乗誤差
を選んだとき、連鎖律より、\(\frac{\partial L}{\partial w_{d,h}}\)は次の式で求められます
\(\frac{\partial L}{\partial y_{n,h}}\)は、\(y_{n,h}\)に関する\(L\)の微分です。
\(\frac{\partial y_{n,h}}{\partial w_{d,h}}\)は、\(w_{d,h}\)に関する\(y_{n,h}\)の微分です。
ここで、\(\frac{\partial y_{n,h}}{\partial w_{d,h}}\)は、
になりますため、
バイアスの勾配#
同じく連鎖律より、\(\frac{\partial L}{\partial b_h}\)は次の式で求められます。
まとめると、
ニューラルネットワークにおける誤差逆伝播法の計算例#
連鎖律より勾配を計算する考え方をニューラルネットワークにも適用する計算例を見ましょう。
具体的には、ニューラルネットワークを構成する関数が持つパラメータについての目的関数の勾配を、順伝播で通った経路を逆向きにたどるようにして途中の関数の勾配の掛け算によって求めます。
ここから、手計算を通じて誤差逆伝播法の実装を理解しましよう。
入力
初期パラメータ
活性化関数: シグモイド関数
教師データ $\( o_{1} = 0.01,o_{2} = 0.99 \)$
目的関数は平均二乗誤差関数を用いることにします。
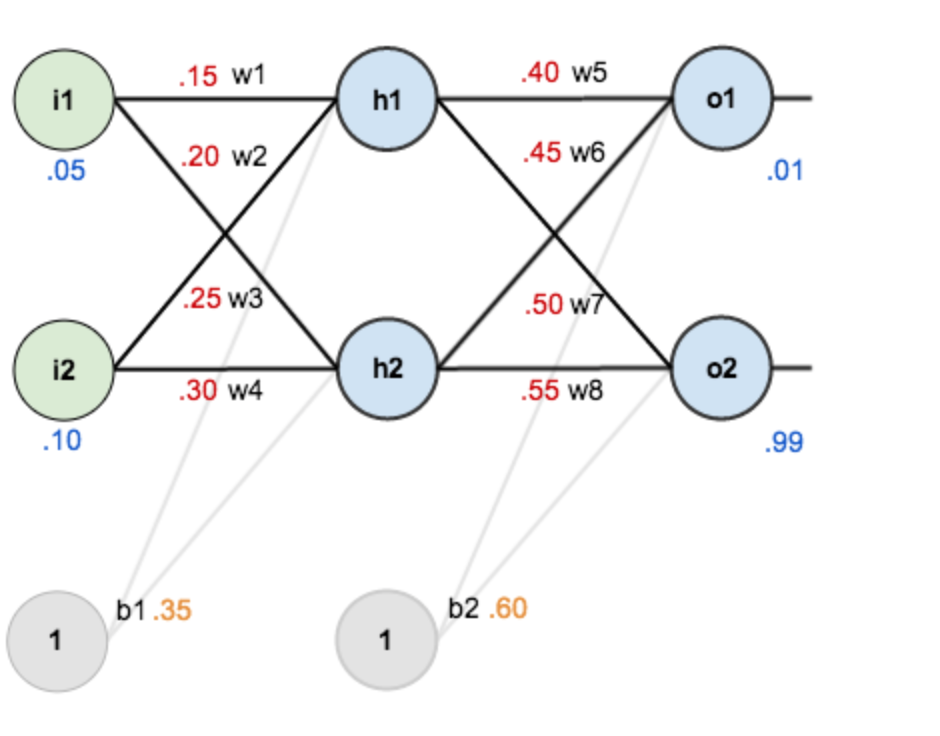
Fig. 6 ニューラルネットワークの実装例#
順伝播の流れ#
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
net_h1= (0.15)*(0.05)+(0.2)*(0.1)+0.35
print("net_h1={}".format(net_h1))
net_h1=0.3775
net_h2= (0.25)*(0.05)+(0.3)*(0.1)+0.35
print("out_h2={}".format(net_h2))
out_h2=0.39249999999999996
net_o1 = (0.4)*net_h1+(0.45)*net_h2+0.6
out_o1= sigmoid(net_o1)
print("out_o1={}".format(out_o1))
net_o2 = (0.5)*net_h1+(0.55)*net_h2+0.6
out_o2= sigmoid(net_o2)
print("out_o2={}".format(out_o2))
out_o1=0.7165932011681534
out_o2=0.7319669364891265
L_1 = 0.5 * np.square(0.01-out_o1)
L_2 = 0.5 * np.square(0.99-out_o2)
L = L_1+L_2
print("Loss={}".format(L))
Loss=0.2829275069009325
例えば、\(w_5\)の勾配を計算する際には、
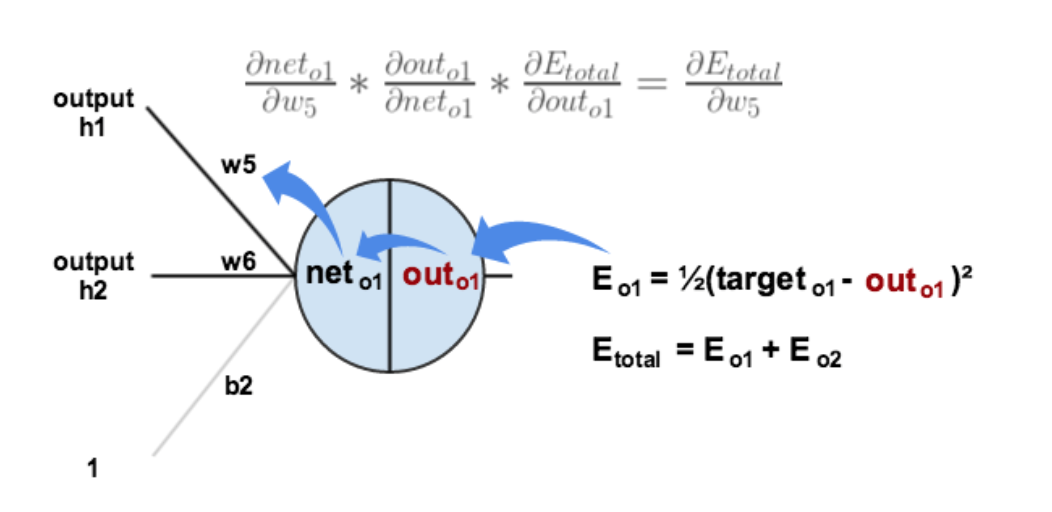
誤差逆伝播法で\(w_5\)の勾配を求める#
\(\frac{\partial L}{\partial out_{o1}}\)を計算する
合成関数の微分\(g(f(x))= g^{\prime}(f(x))f^{\prime}(x)\)によって
d_out_o1 = -(0.01-out_o1)
print("d_out_o1={}".format(d_out_o1))
d_out_o1=0.7065932011681534
\(\frac{\partial out_{o1}}{\partial net_{o1}}\)を計算する
Sigmoid関数の微分は \(f^{\prime}(x)=f(x)(1-f(x))\) なので
Note
シグモイド関数の勾配の証明
d_net_o1 = out_o1*(1-out_o1)
print("d_net_o1={}".format(d_net_o1))
d_net_o1=0.20308738520773184
\(\frac{\partial net_{o1}}{\partial w_5}\)を計算する
d_w5= d_out_o1*d_net_o1*net_h1
print("d_w5={}".format(d_w5))
d_w5=0.05417131252562742
パラメータを更新する
多層ネットワークへの一般化#
以上の計算例には、2層ネットワークの場合の損失関数の勾配を誤差逆伝播法で計算できました。各層での勾配計算がチェーンルールに従っているため、層数が増えても理論的には同じ流れで処理できますため、任意の層数のネットワークに拡張することができます。
入力:学習サンプル\(x_n\)および目標出力\(d_n\)のベア
出力:損失関数\(L_n(w)\)の各層\(l\)のパラメータについての微分\(\frac{\partial {L}}{\partial w_{ji}^{l}}\)
順伝播: 入力データが層を通過して出力に達するまで順番に計算が行われます。
損失の計算: ネットワークの最終出力(予測値)と実際のラベルとの誤差(損失)を損失関数で計算します (\(\delta_j^{L}=z_j-d_j\))
逆伝播: 各隠れ層では、l(=L-1, L-2,…)での\(\delta^{(l)}\)を、\(\delta^{(l)}= (\frac{\partial z^{(l+1)}} {\partial z^{(l)}} \cdot \delta^{(l+1)}) \cdot f'(z^{l})\)のように、次の層からの勾配を逆伝播させ、チェーンルールを使って計算します。
パラメータの更新:逆伝播によって計算された勾配\(\delta^{(l)}\)を用いて、各層の重みとバイアスを更新します。