NumPy#
計算社会科学の研究は、テキスト、画像、ビデオや数値測定結果など幅広いデータセットとソースを扱っています。
これらの多種多様なデータをコンピュータで扱う場合はどのようにすればよいだろうか。
形式に違いがあるにも関わらず、基本的に全てのデータは数値の配列として扱うのに適しています。
テキストデータは文字のシーケンスであり、それぞれの文字には数値の表現があります(通常はUnicode)。テキスト処理や自然言語処理のために、テキストデータは数値の配列として表現されることがあります。一般的な手法には、文字を数値にエンコードする方法(例:ASCII、UTF-8)、単語や文字の出現頻度を数える方法、単語の埋め込み(Word2Vec、GloVe)などがあります。
画像は、各ピクセルに対して数値の輝度や色情報が割り当てられています。カラー画像の場合、各ピクセルはRGB(赤、緑、青)の値で表され、グレースケール画像の場合は単一の輝度値で表されます。
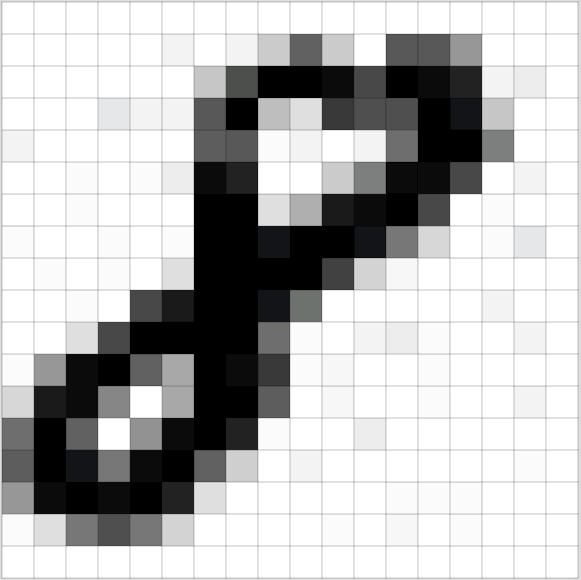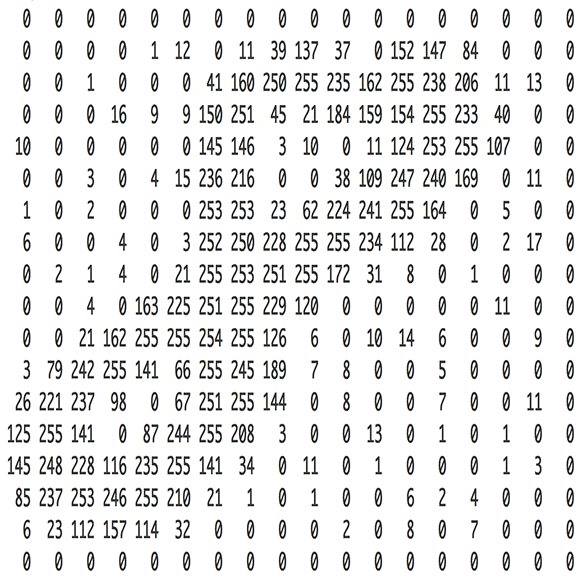
どのようなデータであっても、それらを分析可能にする最初のステップは、数値の配列に変換することです。
このようにデータをベクトル情報として扱うことの利点は、異なるデータを同一の手段で扱うことができるようになる点である。
このため、数値配列の効率的な格納と操作は、データ分析にとって欠かせない要素です。
NumPyは、多次元配列や行列演算を効率的に処理する機能を提供し、科学技術計算やデータ解析に広く利用されています。
import numpy as np
print(np.__version__)
1.26.4
NumPy配列の作成#
Pythonリストから作る配列#
np.arrayを使って、PythonリストからNumPy配列(ndarray)を作成します。
np.array([1, 2, 3, 4, 5, 6])
array([1, 2, 3, 4, 5, 6])
Pythonリストとは異なり、NumPy配列の要素は全て同じ型という制約がります。作成する際、型が一致しない場合、可能であればNumPyは自動的に調整してくれます。
np.array([1, 2, 3.14, 4, 5, 6]) # upcasting: all elements are converted to float
array([1. , 2. , 3.14, 4. , 5. , 6. ])
dtypeキーワードで配列のデータ型を明示的に設定できます。
np.array([1, 2, 3, 4, 5, 6],dtype='float32') # specify data type
array([1., 2., 3., 4., 5., 6.], dtype=float32)
配列の構築#
NumPyの組み込み関数で配列を作成できます。
np.zeros(10, dtype=int) # create an array of 10 zeros
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
np.ones((3, 5), dtype=float) # create a 3x5 array of floating-point ones
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
np.full((3, 5), 3.14) # create a 3x5 array filled with 3.14
array([[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14]])
np.arange(0, 20, 2) # create an array filled with a linear sequence
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
np.linspace(0, 1, 5) # create an array of five values evenly spaced between 0 and 1
array([0. , 0.25, 0.5 , 0.75, 1. ])
np.eye(3) # create a 3x3 identity matrix
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
NumPyは、様々な種類の確率分布関数に基づく乱数値を生成できます。
np.random.random((3, 3)) # create a 3x3 array of uniformly distributed random values between 0 and 1
array([[0.6958738 , 0.33032063, 0.9649371 ],
[0.05650145, 0.99326052, 0.1400965 ],
[0.61352255, 0.44608042, 0.79414483]])
np.random.normal(0, 1, (3, 3)) # create a 3x3 array of normally distributed random values with mean 0 and standard deviation 1
array([[-0.31996381, 0.23299519, 1.17583346],
[-0.61571703, 0.07986088, 0.91252649],
[ 1.37445045, -0.55009263, -0.41731686]])
np.random.randint(0, 10, (3, 3)) # create a 3x3 array of random integers in the interval [0, 10)
array([[7, 1, 9],
[5, 8, 5],
[2, 5, 2]])
Note
配列作成方法の一覧は、公式チュートリアルを参照してください。
NumPy配列の属性#
import numpy as np
np.random.seed(0) # seed for reproducibility
x1 = np.random.randint(10, size=6) # one-dimensional array
x2 = np.random.randint(10, size=(3, 4)) # two-dimensional array
x3 = np.random.randint(10, size=(3, 4, 5)) # three-dimensional array
NumPy配列には、ndim(次元数)、shape(各次元のサイズ)、size(配列の合計サイズ)、dtype(配列のデータ型)などの属性を持ちます。
print("x3 ndim: ", x3.ndim) # number of dimensions
print("x3 shape:", x3.shape) # the size of each dimension
print("x3 size: ", x3.size) # total size of the array
print("dtype:", x3.dtype) # data type of the array
x3 ndim: 3
x3 shape: (3, 4, 5)
x3 size: 60
dtype: int64
配列の形状は、reshape() メソッドによって変更することができます。
x1
array([5, 0, 3, 3, 7, 9])
x1.reshape((2, 3)) # reshape
array([[5, 0, 3],
[3, 7, 9]])
配列のインデクス#
1次元ndarrayでは、Pythonリストと同様に、\(i\)番目(\(0\)から)の値にアクセスできます。
x1= np.array([1,2,3,4,5,6,7,8,9])
x1[1]
2
x1[3:6]
array([4, 5, 6])
ndarrayから切り出した一部にの値を指定することができます。
Pythonのリストとは異なって, ndarrayのスライスは元のndarrayのビューであり、ndarrayのコピーではないことを注意する必要があります。
つまり、スライスへの変更は、元のndarrayに反映されます。
x1_slice = x1[3:6]
x1_slice
array([4, 5, 6])
x1_slice[0]=12345
x1
array([ 1, 2, 3, 12345, 5, 6, 7, 8, 9])
多次元配列では、カンマで区切ったインデクスで要素にアクセスします。
import matplotlib.pyplot as plt
import numpy as np
# Create a 3x3 matrix
matrix = np.arange(9).reshape(3, 3)
# Set the background color for all cells
background_color = '#E0E0E0' # Light gray
# Create a figure and axis
fig, ax = plt.subplots()
# Create a heatmap plot with the specified background color
heatmap = ax.imshow(matrix, cmap='Blues', vmin=0, vmax=8)
# Loop over each cell and add the index value as text
for i in range(matrix.shape[0]):
for j in range(matrix.shape[1]):
ax.text(j, i, f'({i},{j})', ha='center', va='center', color='black')
# Set axis labels
ax.set_xticks(np.arange(matrix.shape[1]))
ax.set_yticks(np.arange(matrix.shape[0]))
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.tick_params(length=0)
ax.set_xlabel('axis 1')
ax.set_ylabel('axis 0')
# Set the title
ax.set_title('Index of 3x3 Matrix')
# Remove the colorbar
plt.colorbar(heatmap).remove()
# Show the plot
plt.show()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[24], line 1
----> 1 import matplotlib.pyplot as plt
2 import numpy as np
4 # Create a 3x3 matrix
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib/pyplot.py:2500
2498 dict.__setitem__(rcParams, "backend", rcsetup._auto_backend_sentinel)
2499 # Set up the backend.
-> 2500 switch_backend(rcParams["backend"])
2502 # Just to be safe. Interactive mode can be turned on without
2503 # calling `plt.ion()` so register it again here.
2504 # This is safe because multiple calls to `install_repl_displayhook`
2505 # are no-ops and the registered function respect `mpl.is_interactive()`
2506 # to determine if they should trigger a draw.
2507 install_repl_displayhook()
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib/pyplot.py:277, in switch_backend(newbackend)
270 # Backends are implemented as modules, but "inherit" default method
271 # implementations from backend_bases._Backend. This is achieved by
272 # creating a "class" that inherits from backend_bases._Backend and whose
273 # body is filled with the module's globals.
275 backend_name = cbook._backend_module_name(newbackend)
--> 277 class backend_mod(matplotlib.backend_bases._Backend):
278 locals().update(vars(importlib.import_module(backend_name)))
280 required_framework = _get_required_interactive_framework(backend_mod)
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib/pyplot.py:278, in switch_backend.<locals>.backend_mod()
277 class backend_mod(matplotlib.backend_bases._Backend):
--> 278 locals().update(vars(importlib.import_module(backend_name)))
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/importlib/__init__.py:127, in import_module(name, package)
125 break
126 level += 1
--> 127 return _bootstrap._gcd_import(name[level:], package, level)
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib_inline/__init__.py:1
----> 1 from . import backend_inline, config # noqa
3 __version__ = "0.2.1"
5 # we can't ''.join(...) otherwise finding the version number at build time requires
6 # import which introduces IPython and matplotlib at build time, and thus circular
7 # dependencies.
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib_inline/backend_inline.py:236
231 ip.events.unregister("post_run_cell", configure_once)
233 ip.events.register("post_run_cell", configure_once)
--> 236 _enable_matplotlib_integration()
239 def _fetch_figure_metadata(fig):
240 """Get some metadata to help with displaying a figure."""
File ~/opt/anaconda3/envs/jupyterbook_1/lib/python3.9/site-packages/matplotlib_inline/backend_inline.py:215, in _enable_matplotlib_integration()
211 ip = get_ipython()
213 import matplotlib
--> 215 if matplotlib.__version_info__ >= (3, 10):
216 backend = matplotlib.get_backend(auto_select=False)
217 else:
AttributeError: module 'matplotlib' has no attribute '__version_info__'
x2= np.array([[1,2,3],[4,5,6],[7,8,9]])
x2[1,1]
5
x2[1,-1]
6
インデクスを指定し、要素の値を変更するもできます。
x2[1,-1]=12
x2
array([[ 1, 2, 3],
[ 4, 5, 12],
[ 7, 8, 9]])
ndarrayにおける、比較演算子もベクトル演算子として定義されていますので、真偽値配列をインデックス参照として渡すことができます。
x2>10
array([[False, False, False],
[False, False, True],
[False, False, False]])
x2[x2>10]=100
x2
array([[ 1, 2, 3],
[ 4, 5, 100],
[ 7, 8, 9]])
数学演算#
配列の算術演算#
NumPyはベクトル演算の機能を提供しています。
同じサイズの
ndarray同士の算術演算は、同位置の要素同士で計算されます。
arr=np.array([[1,2,3],[4,5,6]])
arr
array([[1, 2, 3],
[4, 5, 6]])
arr*arr
array([[ 1, 4, 9],
[16, 25, 36]])
arr+arr
array([[ 2, 4, 6],
[ 8, 10, 12]])
arr-arr
array([[0, 0, 0],
[0, 0, 0]])
スカラーと
ndarrayとの算術演算の場合、要素ごとに計算されます。
1/arr
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
arr**0.5
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
ユニバーサル関数: すべての要素への関数適用#
ユニバーサル関数は、NumPy配列の各要素に対して要素ごとの演算を行うための関数です。これにより、繰り返し処理を書く必要なく、高速かつ効率的な計算が可能になります。
例えば、sqrt(平方根)exp(指数)を計算する:
arr= np.arange(10)
arr
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.sqrt(arr)
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
np.exp(arr)
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])
このような引数に一つのndarrayを取ることから単項ufuncと呼ばれます。一方、複数なndarrayを引数として受け取る関数もあります。
x1= np.random.randint(10, size=6)
x1
array([4, 3, 4, 4, 8, 4])
x2= np.random.randint(10, size=6)
x2
array([3, 7, 5, 5, 0, 1])
np.maximum(x1,x2)
array([4, 7, 5, 5, 8, 4])
関数名 |
説明 |
|---|---|
|
配列の各要素の絶対値を計算します。 |
|
配列の各要素の平方根を計算します。 |
|
配列の各要素の指数関数を計算します。 |
|
配列の各要素の自然対数を計算します。 |
|
配列の各要素の正弦を計算します。 |
|
配列の各要素の余弦を計算します。 |
|
2つの配列の要素ごとの加算を行います。 |
|
2つの配列の要素ごとの減算を行います。 |
|
2つの配列の要素ごとの乗算を行います。 |
|
2つの配列の要素ごとの除算を行います。 |
|
2つの配列の要素ごとのべき乗を計算します。 |
Note
公式ドキュメンタリーでユニバーサル関数一覧を確認できます。
与えられた二つのサイズが (5,2) の配列の各要素は、二次元空間での位置を表しています。二つの配列における同じ行である要素で表示する点間のユークリッド距離を計算してください。
array1 = np.array([[1, 2],
[0, 4],
[5, 6],
[-2,2],
[3, 6]])
array2 = np.array([[6, 3],
[7, 0],
[5, 5],
[9, 1],
[5, 6]])
統計関数#
NumPyの統計関数は、ndarray配列全体、あるいは特定の軸を中心とした統計処理を提供します。
いくつかの統計値を計算してみましょう。
arr=np.arange(20).reshape(5,4)
arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
arr.mean()
9.5
arr.sum()
190
mean()やsumはどの軸を中心に処理することを引数axisで指定することができます。
axis=0は列ごとの計算axis=1は行ごとの計算
arr.mean(axis=0)
array([ 8., 9., 10., 11.])
arr.sum(axis=1)
array([ 6, 22, 38, 54, 70])
関数名 |
説明 |
|---|---|
|
配列の平均値を計算します。 |
|
配列の中央値を計算します。 |
|
配列の最小値を取得します。 |
|
配列の最大値を取得します。 |
|
配列の要素の合計値を計算します。 |
|
配列の要素の積を計算します。 |
|
配列の標準偏差を計算します。 |
|
配列の分散を計算します。 |
|
配列のパーセンタイル値を計算します。 |
平均5、標準偏差1の正規分布に従う乱数を生成してください。
生成された配列の平均と標準偏差を計算しよう。
行列計算#
NumPyは、高度な行列計算を効率的に行うための多くの機能を提供しています。
NumPyで内積(ドット積)を計算するために関数dotを提供します。
x= np.array([[1,2,3],
[4,5,6]])
y= np.array([[6,23],
[-1,7],
[8,9]])
x.dot(y)
array([[ 28, 64],
[ 67, 181]])
np.dot(x,y)
array([[ 28, 64],
[ 67, 181]])
標準的な行列の分解、逆、行列式の計算といった機能はnumpy.linalgモジュールで提供されています。
from numpy.linalg import inv, qr
x= np.array([[1,2,3],
[6,4,9],
[1,12,5]])
mat= x.T.dot(x)
mat.dot(inv(mat))
array([[ 1.00000000e+00, -7.77156117e-16, -1.77635684e-15],
[-8.88178420e-16, 1.00000000e+00, -8.88178420e-15],
[ 6.66133815e-15, -1.49880108e-15, 1.00000000e+00]])
# Create the identity matrix
identity_matrix = np.eye(mat.shape[0])
# Check if the dot product is close to the identity matrix
if np.allclose(mat.dot(inv(mat)), identity_matrix):
print("The dot product is equal to the identity matrix.")
else:
print("The dot product is not equal to the identity matrix.")
The dot product is equal to the identity matrix.
関数名 |
説明 |
|---|---|
|
行列の逆行列を計算します。 |
|
行列の行列式を計算します。 |
|
行列の固有値と固有ベクトルを計算します。 |
|
線形方程式を解きます。 |
|
最小二乗法を用いて線形方程式を解きます。 |
|
行列のQR分解を計算します。 |
|
特異値分解(SVD)を計算します。 |
|
行列のべき乗を計算します。 |
|
ベクトルまたは行列のノルムを計算します。 |
|
行列の逆行列を計算します。 |
|
行列のランクを計算します。 |
特定のベクトル(\(v\))を他のベクトル(\(u\))に射影する結果を計算しよう。
ヒント
射影の公式は以下になります:NumPyの応用例:線型回帰モデル#
単回帰モデル#
\(n\)個のデータ\((x_1,y_1),...(x_n,y_n)\)が観測され、各\(y_i\)が
が得られます。
最小二乗法#
最小二乗法の目標は、与えられたデータセットに対して予測された値(モデルの出力)と実際の値(データセットの出力)の差を最小化することである。
\(E[h(\alpha,\beta)]=0\)から,母集団における\(\alpha\)と\(\beta\)を求めるが、これはあくまでも母集団の概念である。実際に持っているのは母集団に対応する標本であって、母集団そのもののは手に入りません。
データから得られる推定値を\(\hat{\alpha}, \hat{\beta}\)で定義する。
ここで、\(\bar{y}\)は標本平均と呼ぶ。この式を切片について書き直すと、
この式を条件付き期待値ゼロ仮定 \(E(u|x)=0\) より、
に代入すると
ここで、
のため
この式から\(\hat{\beta}\)を解くと、
そして、\( \hat{\alpha} \)も得られる
任意の推定値\(\hat{\alpha},\hat{\beta}\)に関して、\(i\)に関する当てはめる値(fitted value)を
と定義する。
回帰直線と観測値との差
を残差(residual)といいます。
残差の二乗の和をとったもの
を残差平方和(residual sum of squares, RSS)といいます。
ここで、残差平方和を最小にするような\(\hat{\alpha}\)と\(\hat{\beta}\)を選びます。
線形回帰モデルのデータをシミュレーションで生成します
# 線形回帰モデルのデータをシミュレーションで生成します
import numpy as np
# サンプルデータ
# パラメータ
beta_0 = 2.5 # 切片
beta_1 = 0.8 # 傾き
n = 100 # データ数
# 説明変数を一様分布から生成
x = np.random.uniform(low=0, high=10, size=n)
# ノイズ項を標準正規分布から生成
epsilon = np.random.normal(loc=0, scale=1, size=n)
# 目的変数を生成
y = beta_0 + beta_1 * x + epsilon
# パラメータの推定
x_mean = np.mean(x)
y_mean = np.mean(y)
# β₁の推定
numerator = np.sum((x - x_mean) * (y - y_mean))
denominator = np.sum((x - x_mean) ** 2)
beta = numerator / denominator
print("beta: ", beta)
# β₀の推定
alpha = y_mean - beta * x_mean
print("alpha: ", alpha)
beta: 0.7559967477987241
alpha: 2.6018977549592948
# 予測値の計算
y_pred = alpha + beta * x
# 残差の計算
residuals = y - y_pred
# 残差の合計の確認
residual_sum = np.sum(residuals)
print("残差の合計:", residual_sum)
残差の合計: -1.7319479184152442e-14
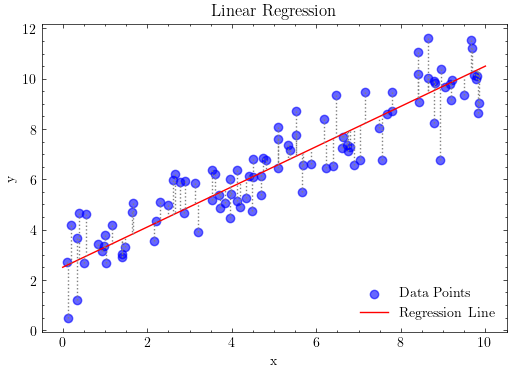
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import scienceplots
plt.style.use('science')
# Creating a figure and axes
fig, ax = plt.subplots(figsize=(6, 4))
# Scatter plot of the data points
ax.scatter(x, y, color='blue', label='Data Points',alpha=0.6)
# Regression line
x_line = np.linspace(0, 10, 100)
y_line = beta_0 + beta_1 * x_line
ax.plot(x_line, y_line, color='red', label='Regression Line')
# Vertical lines and residuals
for i in range(n):
x_i = x[i]
y_i = y[i]
y_pred_i = beta_0 + beta_1 * x_i
ax.vlines(x_i, y_i, y_pred_i, color='gray', linestyle='dotted')
# Plot settings
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('Linear Regression')
ax.legend(loc="lower right")
# Display the plot
plt.show()
母集団回帰係数、誤差項とサンプルサイズを指定し、観測データ(\(x\),\(y\))を生成する関数を作成しなさい
観測データ(\(x\),\(y\))で、最小二乗法で回帰係数を推定する関数を作成しなさい
一定な母集団回帰係数、誤差項サンプルサイズを設定し、観測データを作成し、回帰係数を推定するといった推定プロセスを100回を行いなさい。
毎回の推定値を格納し、その平均と標準偏差を計算しなさい。
サンプルサイズが \(20, 50, 100, 200, 500,1000\)である場合、推定値の平均と標準偏差を比較しなさい
重回帰モデル#
\(k\)個の説明変数\(x_1,...,x_k\)が考えられ、\(y\)との間に
なる線型関係が想定されます。これを重回帰モデルといいます。
\(\beta_1,....,\beta_k\)は偏回帰係数(partial regression coefficient)と呼びます。
重回帰モデルを行列を用いて
と表されます。それぞれの対応するベクトル及び行列とおくと、
ここで、誤差\(\mathbf{u}\)について、
不偏性: \(E(\mathbf{u})=0\)
等分散性、無相関性: 平均ベクトル\(E(\mathbf{u})=0\)年、\(Cov(\mathbf{u})=E[\mathbf{u} \mathbf{u}^T]=\sigma^2 \mathbf{I}\)と仮定する
回帰係数ベクトル\(\mathbf{\beta}\)の最小二乗推定量は、
を最小化することより得られる。
この式を行列を用いて表すと、
\(min\ h(\mathbf{\beta})\)という最小化問題を解くために、
を得ることができます。ここで、\(X^T X\beta=X^T Y\)のため、
\(\mathbf{X}\)はフル・ランクであるとすると、\(X^TX\)の逆行列が存在しますので、