
PyTorchはPythonのオープンソースの機械学習・深層学習ライブラリです。
柔軟性を重視した設計であり、さらに、機械学習・深層学習モデルをPythonの慣用的なクラスや関数の取り扱い方で実装できるようになっています。
GPUを使用した計算をサポートしますので、CPU上で同じ計算を行う場合に比べて、数十倍の高速化を実現します。
#pip install torch torchvision torchaudio
import torch
import numpy as np1テンソル¶
深層学習モデルは通常、入力から出力にどのようにマッピングされるのかを対応つけるデータ構造を表します。一般的に、このようなある形式のデータから別の形式への変換は膨大な浮動小数点数の計算を通じて実現されています。
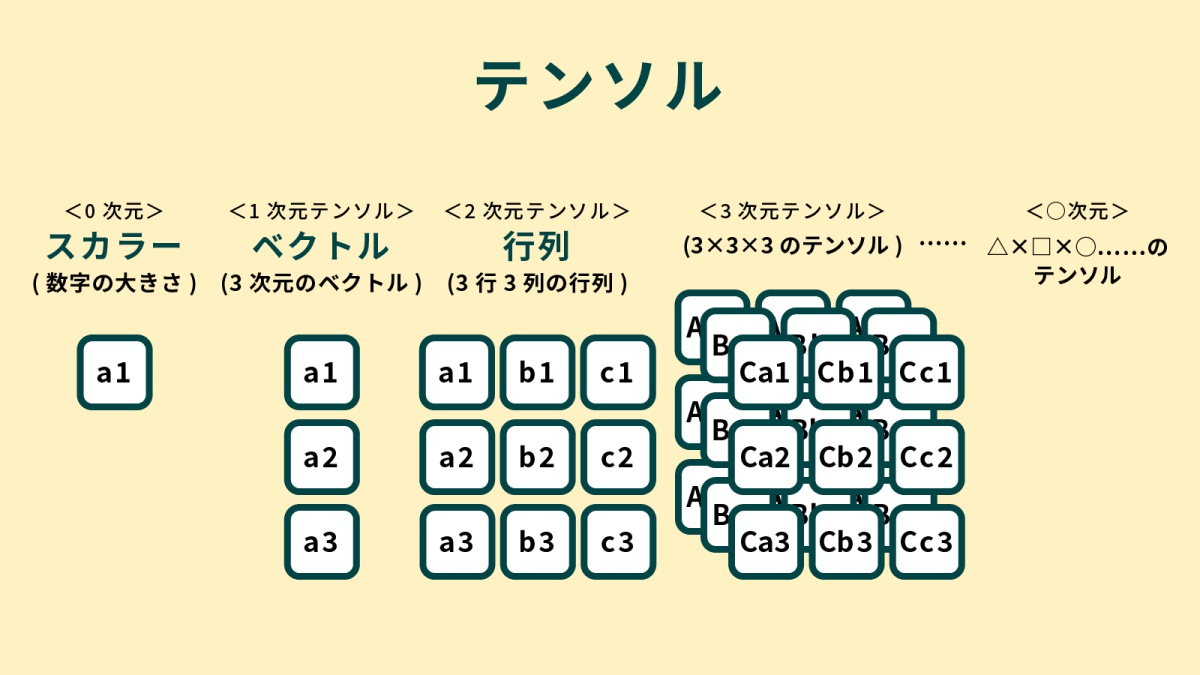
データを浮動小数点数を扱うためには、Pytorchは基本的なデータ構造として「テンソル」を導入しています。
深層学習の文脈でのテンソルとは、ベクトルや行列を任意の次元数に一般化したものを指します。つまり、多次元配列を扱います。
x = torch.ones(5, 3)
print(x)tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
x = torch.rand(5, 3)
print(x)tensor([[0.4255, 0.4716, 0.5521],
[0.3552, 0.6625, 0.4613],
[0.1074, 0.1958, 0.9927],
[0.3990, 0.8811, 0.9015],
[0.1934, 0.7353, 0.5517]])
x = torch.tensor([5.5, 3])
print(x)tensor([5.5000, 3.0000])
1.1.2テンソル要素の型¶
テンソル要素の型は、引数に適切なdtypeを渡すことで指定します。
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)1.1.3テンソルの操作(変形・変換等)¶
PyTorchにはテンソルに対する操作(変形・演算など)が多く用意されています。
x = torch.rand(5, 3)
y = torch.rand(5, 3)
print(x + y)tensor([[0.8623, 0.7859, 1.2484],
[1.4111, 1.1073, 0.7135],
[1.1091, 0.6681, 1.7415],
[0.6487, 1.0433, 1.1790],
[1.1507, 0.5620, 1.5918]])
print(torch.add(x, y))tensor([[0.8623, 0.7859, 1.2484],
[1.4111, 1.1073, 0.7135],
[1.1091, 0.6681, 1.7415],
[0.6487, 1.0433, 1.1790],
[1.1507, 0.5620, 1.5918]])
1.1.4テンソルの一部指定や取り出し(Indexing)¶
Pytorchテンソルは、Numpyや他のPythonの科学計算ライブラリーと同じく、テンソルの次元ごとのレンジインデックス記法で一部指定や取り出しを行えます。
x[3:,:]tensor([[0.0979, 0.9661, 0.7045],
[0.8860, 0.1049, 0.5975]])x[1:,0]tensor([0.9718, 0.8437, 0.0979, 0.8860])1.1.5テンソルの微分機能¶
PyTorchテンソルは、テンソルに対して実行された計算を追跡し、計算結果の出力テンソルの微分を、各テンソルの要素に対して解析的に計算することができます。
具体的には、requires_grad=True を設定したテンソルに対して行われたすべての演算が計算グラフとして記録され、.backward()メソッドを呼び出すことで、損失関数などの出力に対する各パラメータの勾配が自動的に計算されます。
# 微分を計算するためのテンソルを作成
x = torch.tensor(2.0, requires_grad=True)
# 関数の定義
y = x ** 2
# 勾配を計算
y.backward()
# 勾配の値を表示
print(x.grad) # 4.0 (これは2*xの値、x=2のとき)tensor(4.)
1.1.6CUDA Tensors(CUDA テンソル)¶
tensorは .to メソッドを使用することであらゆるデバイス上のメモリへと移動させることができます。
if torch.cuda.is_available():
device = torch.device("cuda") # a CUDA device object
y = torch.ones_like(x, device=device) # directly create a tensor on GPU
x = x.to(device) # or just use strings ``.to("cuda")``
z = x + y
print(z)
print(z.to("cpu", torch.double)) # ``.to`` can also change dtype together!2学習データセットの作成¶
深層学習を実装する際には、大量のデータを扱う必要があります。しかし、その際には次のような課題が生じます:
データの読み込みや前処理のコードが複雑になる(
for文で個別処理する必要がある)学習時にデータをランダムにシャッフルしたり、ミニバッチに分割したりする必要がある
2.1Datasetクラス¶
PyTorchのtorch.utils.data.Datasetは、これらの課題を解決するために用意されたデータ管理の基本インターフェースです
Pytorchで深層学習を実装する際には、特徴量行列とラベルをDatasetというクラスに渡して、特徴量行列とラベルを一つのデータベース的なものにまとめる働きをします。
一般的には、PyTorchのtorch.utils.data.Datasetクラスを継承して定義します。以下に示すメソッドを定義するように指定されています。
__init__(self): 初期実行関数です。Datasetを定義する際に必要な情報を受け取ります。__len__(self): データ全体の数を返す関数です。__getitem__(self, index): 指定されたindexに対応するデータと正解ラベル(ターゲット)を返します。これにより、データの取得方法を統一化します。
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
# データセットのサイズを返す
return len(self.data)
def __getitem__(self, index):
# 指定されたインデックスのデータとラベルを返す
return self.data[index], self.labels[index]# サンプルデータ
data = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
labels = torch.tensor([0, 1, 0])
# カスタムデータセットのインスタンスを作成
dataset = CustomDataset(data, labels)dataset[0](tensor([1., 2.]), tensor(0))2.2DataLoaderクラス¶
機械学習のトレーニングには、データセットのサンプリング、シャッフル、バッチ分割などの操作が必要されます。これらの操作を効率化にするためにDataLoaderクラスが用意されます。
バッチ処理: 指定したバッチサイズでデータを分割します
シャッフル: データの順序をランダムに並べ替えられます
# サンプルデータ
data = torch.randn(100, 3) # 100個のデータ、3つの特徴
labels = torch.randint(0, 2, (100,)) # 100個のラベル (0または1)
dataset = CustomDataset(data, labels)from torch.utils.data import DataLoader
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)dataloader<torch.utils.data.dataloader.DataLoader at 0x33d9997f0>for batch_data, batch_labels in dataloader:
print("Batch data shape:", batch_data.shape)
print("Batch labels shape:", batch_labels.shape)Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
Batch data shape: torch.Size([10, 3])
Batch labels shape: torch.Size([10])
# 最初のバッチを取得
data_iter = iter(dataloader)
sample_data, sample_label = next(data_iter)
# 1つ目のサンプルのデータとラベルを確認
print("Sample data:", sample_data[0])
print("Sample label:", sample_label[0])Sample data: tensor([ 1.6532, 1.1142, -1.5178])
Sample label: tensor(1)
DataLoaderは反復処理が可能なので、トレーニング中のループで直接に使用することができます。
イテレーターとは
iter(dataloader)は、DataLoaderオブジェクトからイテレーターを作成します。 イテレーターは順次データを取り出すためのオブジェクトで、forループやnext()を使用して1つずつデータを取得できます。
3深層学習モデルの構築¶
torch.nnで用意されているクラス、関数は、独自のニューラルネットワークを構築するために必要な要素を網羅しています。
PyTorchの全てのモジュールは、nn.Moduleを継承しています。
そしてニューラルネットワークは、モジュール自体が他のモジュール(レイヤー)から構成されています。
この入れ子構造により、複雑なアーキテクチャを容易に構築・管理することができます。
3.1クラスの定義¶
nn.Moduleを継承し、独自のネットワークモデルを定義し、その後ネットワークのレイヤーを __init__で初期化します。
nn.Module を継承した全モジュールは、入力データの順伝搬関数であるforward関数を持ちます。
from torch import nnclass NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 3),
nn.ReLU()
)
def forward(self, x):
logits = self.linear_relu_stack(x)
return logitsこのクラスは、PyTorchのnn.Moduleを継承した単純なニューラルネットワークの実装を示しています。入力は固定長の512とされており、出力は3の次元を持つベクトルです。
self.linear_relu_stack: このシーケンシャルな層は、3つの線形層とそれぞれの後に続くReLU活性化関数から構成されています。nn.Sequentialにレイヤーを順に渡すだけで、数のレイヤーを順に積み重ねたモデルを簡単に定義できます。linear layerは、線形変換を施します。linear layerは重みとバイアスのパラメータを保持しています。nn.ReLUという活性化関数を設置することで、ニューラルネットワークの表現力を向上させます。
順伝播メソッド (
forward): 入力テンソルxを受け取り、ネットワークを通して出力を生成する機能を持ちます。
3.2GPUの利用¶
NeuralNetworkクラスのインスタンスを作成し、変数device上に移動させます。
以下でネットワークの構造を出力し確認します。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))Using cpu device
model = NeuralNetwork().to(device)
print(model)NeuralNetwork(
(linear_relu_stack): Sequential(
(0): Linear(in_features=512, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=3, bias=True)
(5): ReLU()
)
)
3.3モデルによる計算¶
ニューラルネットワークの最後のlinear layerは
logitsを出力します。このlogitsはnn.Softmaxモジュールへと渡されます。出力ベクトルの要素の値はの範囲となり、これは各クラスである確率を示します。
X = torch.rand(3, 512, device=device)
logits = model(X)
print(logits)tensor([[0.0000, 0.0000, 0.0957],
[0.0003, 0.0000, 0.0991],
[0.0163, 0.0000, 0.0933]], grad_fn=<ReluBackward0>)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")Predicted class: tensor([2, 2, 2])
おまけ:tensorboard
tensorboardでニューラルネットワークの構造を確認する。
from torch.utils.tensorboard import SummaryWriter
X = torch.rand(3, 28, 28)
writer = SummaryWriter("torchlogs/")
writer.add_graph(model, X)
writer.close()4自動微分¶
ニューラルネットワークを訓練する際、その学習アルゴリズムとして、バックプロパゲーション(back propagation) がよく使用されます。
バックプロパゲーションでは、モデルの重みなどの各パラメータは、損失関数に対するその変数の微分値(勾配)に応じて調整されます。
これらの勾配の値を計算するために、PyTorchにはtorch.autograd という微分エンジンが組み込まれています。
autogradはPyTorchの計算グラフに対する勾配の自動計算を支援します。
シンプルな1レイヤーのネットワークを想定しましょう。
入力をx、パラメータをw と b、そして適切な損失関数を決めます。
PyTorchでは例えば以下のように実装します。
import torch
x = torch.rand(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)4.1勾配情報の保存¶
こののニューラルネットワークでは、wとbが最適したいパラメータです。
そのため、これらの変数に対する損失関数の微分値を計算する必要があります。
これらのパラメータで微分を可能にするために、requires_grad属性をこれらのテンソルに追記します。
そうすると、勾配は、テンソルの grad_fn プロパティに格納されます。
print('Gradient function for z =',z.grad_fn)
print('Gradient function for loss =', loss.grad_fn)Gradient function for z = <AddBackward0 object at 0x17f4ef190>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x17f4ef190>
4.2勾配計算¶
ニューラルネットワークの各パラメータを最適化するために、入力xと出力yが与えられたもとで、損失関数の各変数の偏微分値、
すなわち
、
を求める必要があります。
これらの偏微分値を求めるためにloss.backward()を実行し、w.gradとb.gradの値を導出します。
逆伝搬では、.backward()がテンソルに対して実行されると、autogradは、
各変数の
.grad_fnを計算する各変数の
.grad属性に微分値を代入する微分の連鎖律を使用して、各leafのテンソルの微分値を求める
を行います。
loss.backward()
print(w.grad)
print(b.grad)tensor([[0.0223, 0.0256, 0.0265],
[0.1082, 0.1243, 0.1287],
[0.0092, 0.0106, 0.0109],
[0.1678, 0.1928, 0.1995],
[0.2269, 0.2606, 0.2698]])
tensor([0.2299, 0.2640, 0.2734])
最適化ループを構築し、Pytorchより自動的に逆伝播
import torch.nn.functional as F
def training_loop(n_epochs, learning_rate, model, input, target):
for epoch in range(1, n_epochs + 1):
# Forward pass
outputs = model(input)
# Compute the loss using Binary Cross Entropy with Logits
loss = F.binary_cross_entropy_with_logits(outputs, target)
# Backward pass
loss.backward()
# Update the parameters
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
model.zero_grad()
# Zero the parameter gradients after updating
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
return model# Example usage (with dummy data)
input = torch.rand(10, 512) # 10 samples with 512 features each
target = torch.rand(10, 3) # 10 samples with 3 target values each
n_epochs = 500
learning_rate = 0.01
model = NeuralNetwork()
trained_model = training_loop(n_epochs, learning_rate, model, input, target)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[21], line 7
5 n_epochs = 500
6 learning_rate = 0.01
----> 7 model = NeuralNetwork()
9 trained_model = training_loop(n_epochs, learning_rate, model, input, target)
NameError: name 'NeuralNetwork' is not definedPyTorchにおける勾配計算の初期化
PyTorchの勾配計算メカニズムでは、.backwardを呼び出すと、リーフノードで導関数の計算結果が累積されます。つまり、もし.backwardが以前にも呼び出されていた場合、損失関数が再び計算され、.backwardも再び呼び出され、各リーフの勾配が前の反復で計算された結果の上に累積されます。その結果、勾配の値は誤ったものになります。
このようなことが起こらないようにするためには、反復のルーブのたびにmodel.zero_grad()を用いて明示的に勾配をゼロに設定する必要があります。
4.3最適化関数¶
最適化は各訓練ステップにおいてモデルの誤差を小さくなるように、モデルパラメータを調整するプロセスです。
ここまでの説明は、単純な勾配下降法を最適化に使用しました。これは、シンプルなケースでは問題なく機能しますが、モデルが複雑になったときのために、パラメータ学習の収束を助ける最適化の工夫が必要されます。
4.3.1Optimizer¶
optimというモジュールには、様々な最適化アルゴリズムが実装されています。
ここでは、確率的勾配降下法(Stochastic Gradient Descent)を例として使い方を説明します。
確率的勾配降下法は、ランダムに選んだ1つのデータのみで勾配を計算してパラメータを更新し、データの数だけ繰り返す方法です。
訓練したいモデルパラメータをoptimizerに登録し、合わせて学習率をハイパーパラメータとして渡すことで初期化を行います。訓練ループ内で、最適化(optimization)は3つのステップから構成されます。
optimizer.zero_grad()を実行し、モデルパラメータの勾配をリセットします。勾配の計算は蓄積されていくので、毎イテレーション、明示的にリセットします。続いて、
loss.backwards()を実行し、バックプロパゲーションを実行します。PyTorchは損失に対する各パラメータの偏微分の値(勾配)を求めます。最後に、
optimizer.step()を実行し、各パラメータの勾配を使用してパラメータの値を調整します。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[22], line 1
----> 1 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
NameError: name 'model' is not defineddef training_loop(n_epochs, learning_rate, model, input, target):
# Use Binary Cross Entropy with Logits as the loss function
# Use Adam as the optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(1, n_epochs + 1):
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(input)
loss = F.binary_cross_entropy_with_logits(outputs, target)
# Backward pass and optimize
loss.backward()
optimizer.step()
# Print loss every 100 epochs
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
return modelinput = torch.rand(10, 512) # 10 samples with 512 features each
target = torch.rand(10, 3) # 10 samples with 3 target values each
n_epochs = 1000
learning_rate = 0.001
model = NeuralNetwork()
trained_model = training_loop(n_epochs, learning_rate, model, input, target)Epoch 100, Loss: 0.6899903416633606
Epoch 200, Loss: 0.6868999600410461
Epoch 300, Loss: 0.6844761967658997
Epoch 400, Loss: 0.6822413802146912
Epoch 500, Loss: 0.6804969310760498
Epoch 600, Loss: 0.6790134310722351
Epoch 700, Loss: 0.677758514881134
Epoch 800, Loss: 0.676545262336731
Epoch 900, Loss: 0.675352931022644
Epoch 1000, Loss: 0.6741839051246643
import pandas as pd
train_df = pd.read_csv('./Data/Titanic/train.csv')
train_df.head()test_df = pd.read_csv('./Data/Titanic/test.csv')
test_df.head()print(train_df.dtypes)
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
5.2データの前処理¶
列の削除: 要らない列を消していきます.乗客IDや名前,チケット,港(Embarked)や部屋番号(Cabin)はは生死にあまり関係がなさそうので、削除します。
欠損の補完: 平均値で欠損しているデータを補完します。
文字列を数字に置換
def process_df(df):
df = df.drop(["PassengerId", "Name", "Ticket", "Cabin", "Embarked"], axis=1)
df["Age"] = df["Age"].fillna(df["Age"].mean())
df = df.replace("male", 0)
df = df.replace("female", 1)
return df
train_df = process_df(train_df)
test_df = process_df(test_df)
train_df.head()5.3データセットの作成¶
データセットとデータローダーでミニバッチ学習ためのデータセットを作成します。
features = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]
X = train_df[features]
y = train_df["Survived"]from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)class TitanicDataset(Dataset):
def __init__(self, X, y):
# DataFrameをNumPy配列に変換
self.X = torch.tensor(X.values, dtype=torch.float32) # XをNumPy配列に変換してからテンソル化
self.y = torch.tensor(y.values, dtype=torch.float32) # yも同様にテンソル化
def __len__(self):
return len(self.y)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# データローダーの作成
train_dataset = TitanicDataset(X_train, y_train)
val_dataset = TitanicDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)train_dataset[0](tensor([ 1.0000, 0.0000, 45.5000, 0.0000, 0.0000, 28.5000]), tensor(0.))5.4モデルの定義¶
__init__で行列の掛け算の定義をして,forwardでそれをどの順番で行うかを指定する感じです.
class TitanicModel(nn.Module):
def __init__(self, input_size):
super(TitanicModel, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x5.5モデルの学習¶
損失関数は2乗誤差、最適化関数はAdamを使用します.
import torch.optim as optim
def train_model(model, train_loader, val_loader, n_epochs, learning_rate):
criterion = nn.BCELoss() # 分類の損失関数
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(n_epochs):
model.train()
train_loss = 0.0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(X_batch).squeeze()
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
train_loss += loss.item() * X_batch.size(0)
# 検証データでの評価
model.eval()
val_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in val_loader:
outputs = model(X_batch).squeeze()
loss = criterion(outputs, y_batch)
val_loss += loss.item() * X_batch.size(0)
# 訓練と検証の損失をデータセットのサイズで割り、平均損失を計算します
train_loss /= len(train_loader.dataset)
val_loss /= len(val_loader.dataset)
if epoch % 10 == 0:
print(f"Epoch {epoch+1}/{n_epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
model = TitanicModel(input_size=X_train.shape[1])
train_model(model, train_loader, val_loader, n_epochs=100, learning_rate=0.001)Epoch 1/100, Train Loss: 0.6523, Val Loss: 0.6527
Epoch 11/100, Train Loss: 0.5803, Val Loss: 0.5545
Epoch 21/100, Train Loss: 0.5136, Val Loss: 0.4905
Epoch 31/100, Train Loss: 0.4820, Val Loss: 0.4443
Epoch 41/100, Train Loss: 0.4370, Val Loss: 0.4449
Epoch 51/100, Train Loss: 0.4333, Val Loss: 0.4332
Epoch 61/100, Train Loss: 0.4191, Val Loss: 0.4213
Epoch 71/100, Train Loss: 0.4163, Val Loss: 0.4295
Epoch 81/100, Train Loss: 0.5030, Val Loss: 0.4887
Epoch 91/100, Train Loss: 0.4212, Val Loss: 0.4244
5.6モデルの評価¶
from sklearn.metrics import classification_report
def evaluate_model(model, loader):
model.eval()
predictions = []
true_labels = []
with torch.no_grad():
for X_batch, y_batch in loader:
outputs = model(X_batch).squeeze()
# 出力を0または1に丸める
predicted_classes = outputs.round().numpy()
predictions.extend(predicted_classes)
true_labels.extend(y_batch.numpy())
# レポートの表示
print(classification_report(true_labels, predictions, target_names=["Did not survive", "Survived"],digits=4))
# モデルの評価を実行
evaluate_model(model, val_loader) precision recall f1-score support
Did not survive 0.8125 0.8667 0.8387 105
Survived 0.7910 0.7162 0.7518 74
accuracy 0.8045 179
macro avg 0.8018 0.7914 0.7952 179
weighted avg 0.8036 0.8045 0.8028 179
深層学習の実装を以下の指示に従って、改めて学習を行なってください。
バッチサイズを64に変更しなさい
モデルに一つ隠れ層を追加しなさい
ドロップアウト層を追加しなさい
オプティマイザはAdamWを設定しなさい
epochを増やしなさい