
実に、Attention機構というアイデア自体は汎用的であり、様々な場面で活用されています。Attention機構に基づいたテクニックとして、Transformerの基盤となっているSelf-Attentionというテクニックが挙げられます。
1RNNの問題点¶
今まで、seq2seqやAttention付きseq2seqなどRNNに基づくモデルを説明しました。これらの方法は色々なタスクで広く応用されましたが、RNNの構造による本質的な欠点があります。
それは、RNNは前時点に計算した結果を用いて順番的に計算を行うたま、時間方向で並列的に計算することはできません。この点は、大規模な計算が行われる際、大きなボトルニックになります。そこで、RNNを避けたいモチベーションが生まれます。
並列計算(Parallel Computing)
並列計算(parallel computing)は、コンピュータにおいて特定の処理をいくつかの独立した小さな処理に細分化し、複数の処理装置(プロセッサ)上でそれぞれの処理を同時に実行させることです。
2Self-Attentionの仕組み¶
Self-Attentionは埋め込みを入力として受け取り、それらを相互に参照して(Attntionの計算)、新しい埋め込みを生成します。
2.1Key、Query、Valueの生成¶
入力埋め込みのサイズ
self-attentionライヤの次元数
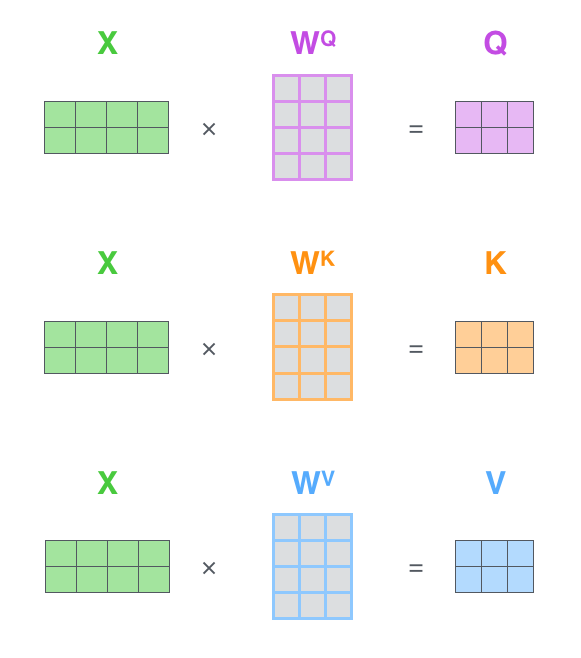
2.2Attention Weightの計算¶
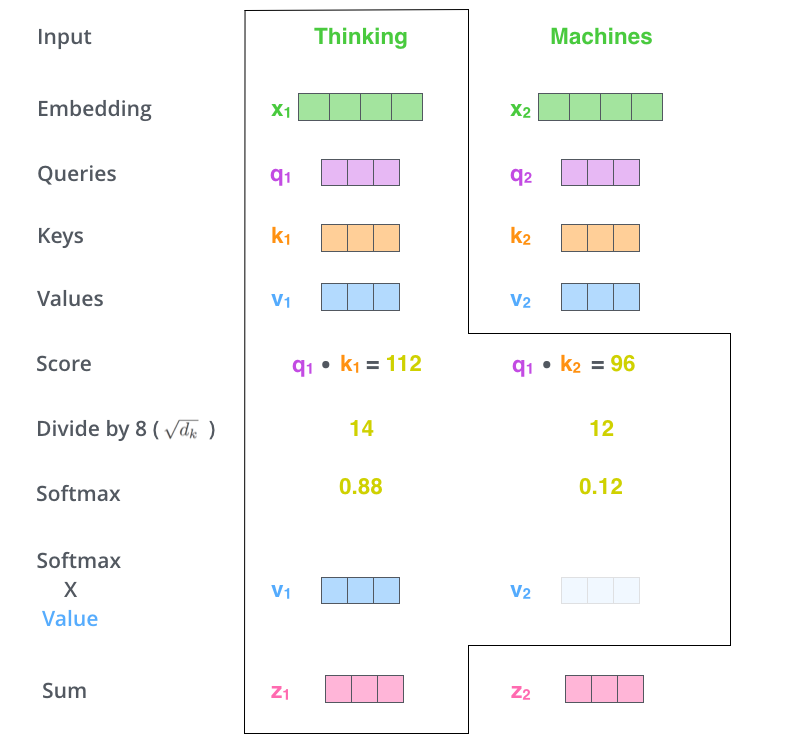

2.3Attention出力¶
Self-Attentionの出力は、入力の各要素の埋め込みが他の要素の埋め込みとの関連性に基づいて、つまり重要度を加味しつつ生成した新たな埋め込みになります。
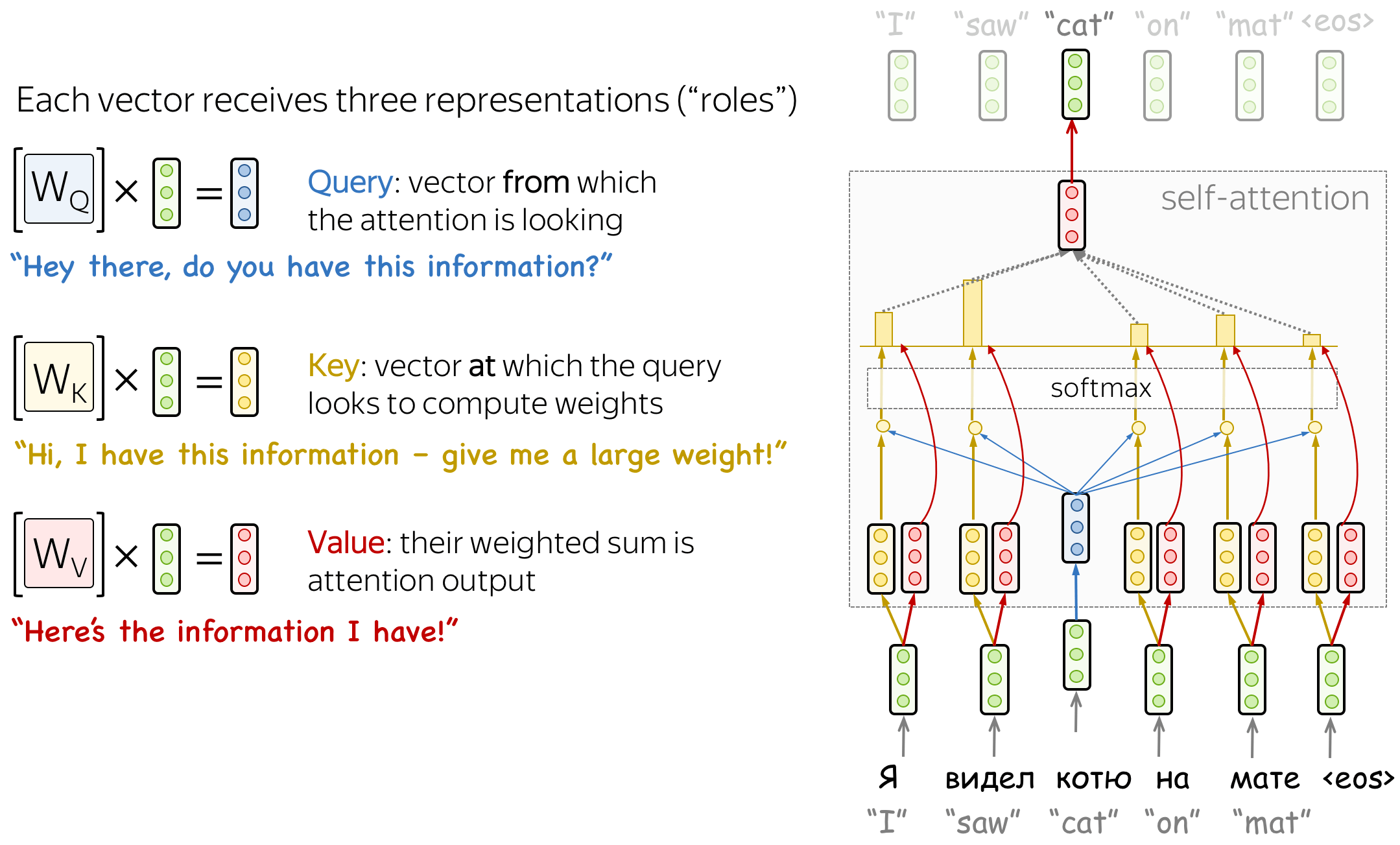
3Multi-head Attention¶
Attention機構の表現力をさらに高めるために、Attention機構を同時に複数適用するMulti-head Attentionが開発されました。
モチベーションとしては、テキストを「理解」するためには、単語の意味や係り受けなどの文法的な情報が重要である場合がありますので、複数のAttention機構を同時に適用することで、複数な観点から文脈化を行うことができます。
具体的には、
Multi-head Attentionでは、D次元の入力埋め込みに対して、個のAttention機構を同時に適用します。
ここで、、、は、番目のヘッド(head)に対応する行列になります。
各ヘッドでAttentionの計算を行い、各ヘッドの出力埋め込みが得られます。
Multi-head Attentionの出力は、個の出力埋め込みを連結して計算されます。
ランダムに初期化された、、を使って、attention weightを計算しなさい
pytorchが提供しているメソッドを用いてattention weightを計算しなさい
pytorch提供しているメソッドを使わず、数式に従って、pytorchの行列計算でattention weightを計算しなさい
import torch
batch_size = 1
sequence_length = 3
embedding_dim = 4
seed=1234
Q = torch.rand(sequence_length, embedding_dim)
K = torch.rand(sequence_length, embedding_dim)
V = torch.rand(sequence_length, embedding_dim)