
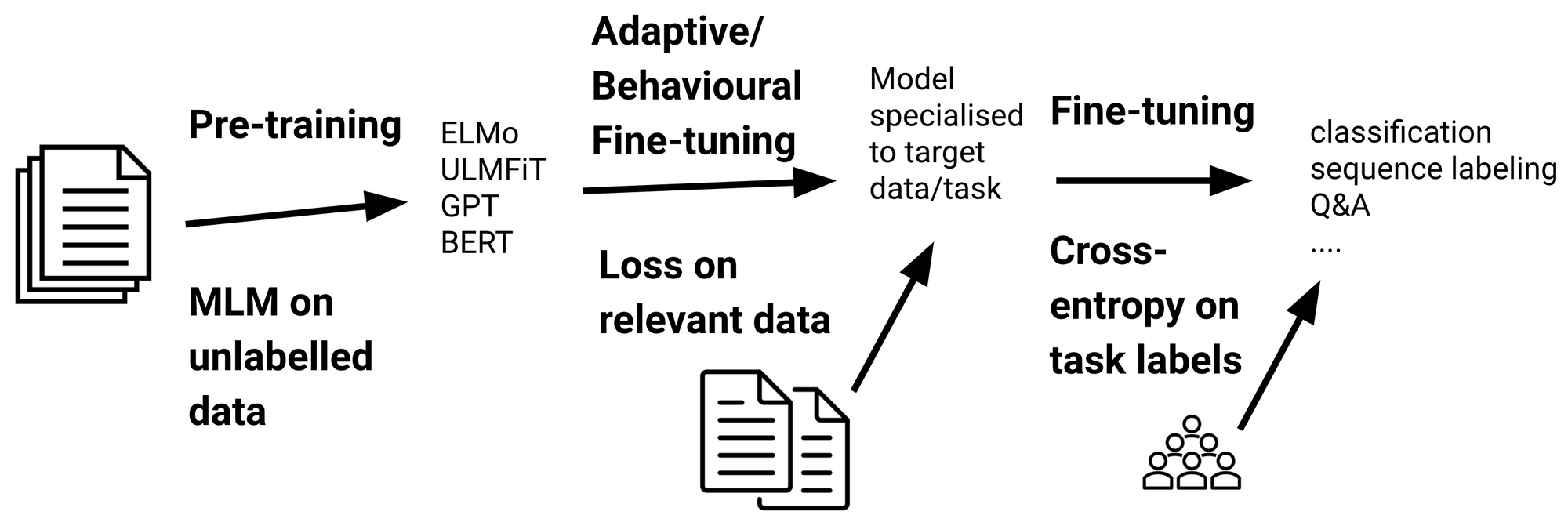
1転移学習とファインチューニング¶
転移学習は、あるタスクの学習で得られた知識を、他の関連するタスクの学習に適用する手法を指します。一般的には、以下のステップで行われることが多いです:
事前学習: 事前学習モデル(pre-trained models)とは、大規模なデータセットを用いて訓練した学習済みモデルのことです。一般的に、大量のデータ(例えば、インターネット上のテキストデータ)を使用して、モデルを事前に学習します。この時点でのモデルは、言語の汎用的な特徴や構造を捉えることができます。
ファインチューニング(fine-tuning): 事前学習モデルを、特定のタスクのデータ(例えば、感情分析や質問応答)でファインチューニングします。事前学習モデルでは汎用的な特徴をあらかじめ学習しておきますので、手元にある学習データが小規模でも高精度な認識性能を達成することが知られています。
2センチメント分析の実装¶
Google ColabdでGPUを使用する
「ランタイム」→「ランタイムのタイプを変更」→「ハードウェア アクセラレータ」→「GPU」
!nvidia-smiSun Jan 4 16:58:32 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:01:00.0 On | Off |
| 30% 35C P8 17W / 300W | 1379MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA RTX A6000 Off | 00000000:02:00.0 Off | Off |
| 30% 26C P8 12W / 300W | 18MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 3971 G /usr/bin/gnome-shell 526MiB |
| 0 N/A N/A 4428 G /usr/bin/Xwayland 4MiB |
| 0 N/A N/A 5204 G /usr/share/code/code 543MiB |
| 1 N/A N/A 3971 G /usr/bin/gnome-shell 4MiB |
+-----------------------------------------------------------------------------------------+
2.1データセット¶
2.1.1Hugging Faceからサンプルデータの取得¶
Hugging Faceのには色々なデータセットが用意されております。ここでは、多言語のセンチメントデータセットを例として使用することにします。その中に、英語と日本語のサプセットが含まれます。
!pip -q install "datasets<4.0.0"from datasets import load_dataset
#dataset = load_dataset("tyqiangz/multilingual-sentiments", "japanese")
dataset = load_dataset("tyqiangz/multilingual-sentiments", "english")2.1.2Weights & Biases (wandb)¶
Weights & Biases (wandb)は、機械学習の実験を追跡・可視化・管理するためのプラットフォームです。
主な機能:
実験追跡: 学習の進捗、損失、精度などのメトリクスをリアルタイムで記録・可視化
ハイパーパラメータ管理: 異なる設定での実験結果を比較
モデル管理: 学習済みモデルのバージョン管理と共有
ここでは、モデルの学習過程を追跡するためにwandbを使用します。wandb.login()でアカウントにログインし、実験結果をクラウドに保存します。
!pip install wandb
import wandb
wandb.login()Requirement already satisfied: wandb in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (0.23.1)
Requirement already satisfied: click>=8.0.1 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (8.1.7)
Requirement already satisfied: gitpython!=3.1.29,>=1.0.0 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (3.1.37)
Requirement already satisfied: packaging in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (24.1)
Requirement already satisfied: platformdirs in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (3.10.0)
Requirement already satisfied: protobuf!=4.21.0,!=5.28.0,<7,>=3.19.0 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (3.20.3)
Requirement already satisfied: pydantic<3 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (2.10.6)
Requirement already satisfied: pyyaml in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (6.0.1)
Requirement already satisfied: requests<3,>=2.0.0 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (2.32.5)
Requirement already satisfied: sentry-sdk>=2.0.0 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (2.48.0)
Requirement already satisfied: typing-extensions<5,>=4.8 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from wandb) (4.12.2)
Requirement already satisfied: gitdb<5,>=4.0.1 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from gitpython!=3.1.29,>=1.0.0->wandb) (4.0.7)
Requirement already satisfied: annotated-types>=0.6.0 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from pydantic<3->wandb) (0.7.0)
Requirement already satisfied: pydantic-core==2.27.2 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from pydantic<3->wandb) (2.27.2)
Requirement already satisfied: charset_normalizer<4,>=2 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from requests<3,>=2.0.0->wandb) (2.0.4)
Requirement already satisfied: idna<4,>=2.5 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from requests<3,>=2.0.0->wandb) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from requests<3,>=2.0.0->wandb) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from requests<3,>=2.0.0->wandb) (2024.2.2)
Requirement already satisfied: smmap<5,>=3.0.1 in /home/lvzeyu/anaconda3/lib/python3.11/site-packages (from gitdb<5,>=4.0.1->gitpython!=3.1.29,>=1.0.0->wandb) (4.0.0)
wandb: Currently logged in as: lvzeyu1995 (lvzeyu1995-tohoku-university) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
Trueimport os
os.environ["WANDB_PROJECT"]="sentiment_analysis"2.1.3サンプルデータの確認¶
取得したデータセットの中身を確認します。
データセットはこのようにtrain, validation, testに分かれています。 [‘text’, ‘source’, ‘label’]といった情報を持っています。
datasetDatasetDict({
train: Dataset({
features: ['text', 'source', 'label'],
num_rows: 1839
})
validation: Dataset({
features: ['text', 'source', 'label'],
num_rows: 324
})
test: Dataset({
features: ['text', 'source', 'label'],
num_rows: 870
})
})dataset.set_format(type="pandas")
train_df = dataset["train"][:]
train_df.head(5)dataset["train"].features{'text': Value(dtype='string', id=None),
'source': Value(dtype='string', id=None),
'label': ClassLabel(names=['positive', 'neutral', 'negative'], id=None)}import matplotlib.pyplot as plt
train_df["label"].value_counts(ascending=True).plot(kind="barh", title="Train Dataset")<Axes: title={'center': 'Train Dataset'}>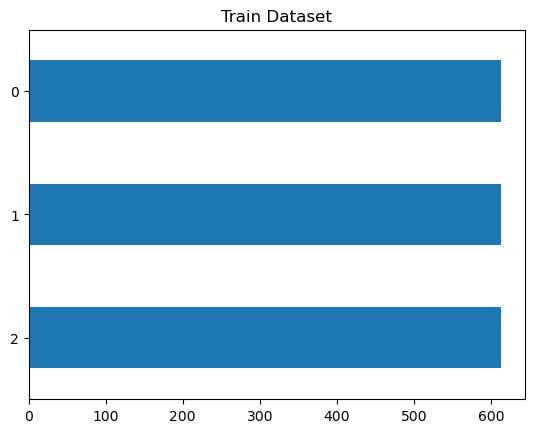
2.1.4テキストの確認¶
Transformerモデルは、最大コンテキストサイズ(maximum context size)と呼ばれる最大入力系列長があります。
モデルのコンテキストサイズより長いテキストは切り捨てる必要があり、切り捨てたテキストに重要な情報が含まれている場合、性能の低下につながることがあります。
train_df["text_length"]=train_df["text"].str.len()train_df.boxplot(column="text_length", by="label", figsize=(12, 6))
<Axes: title={'center': 'text_length'}, xlabel='label'>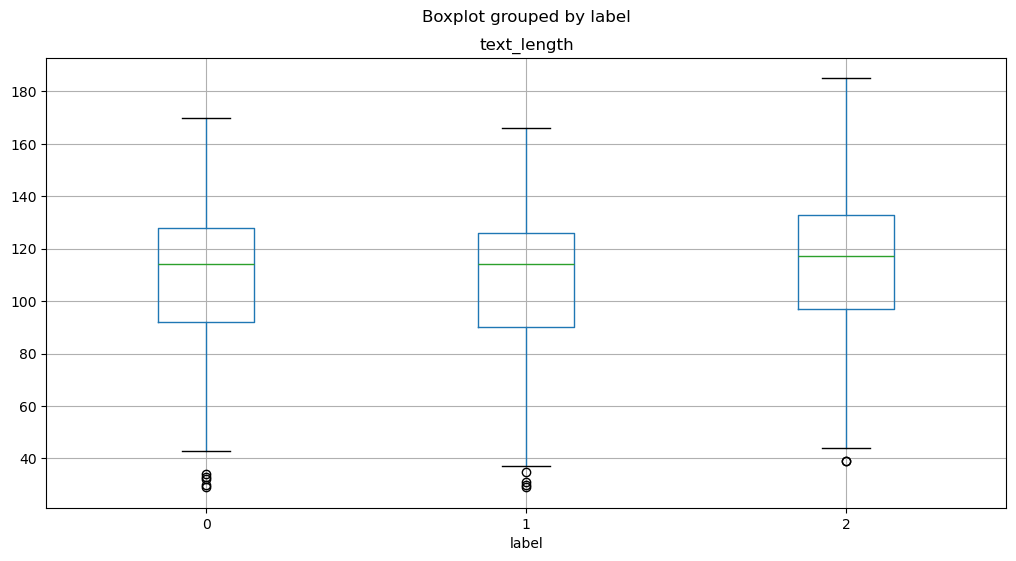
2.2トークン化¶
コンピュータは、入力として生の文字列を受け取ることができません。その代わりに、テキストがトークン化され、数値ベクトルとしてエンコードされていることが想定しています。
トークン化は、文字列をモデルで使用される最小単位に分解するステップです。
Transformerライブラリー は便利なAutoTokenizerクラスを提供しており、事前学習済みモデルに関連つけられたトークナイザーを素早く使用することができます。
2.2.1トークナイザの動作確認¶
tokenizerテキストを数値形式(トークン)に変換します。
入力テキストをトークンに分割します
特殊トークンが自動的に付加されます
トークンをトークンIDに変換します
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)train_df["text"][0]'okay i\\u2019m sorry but TAYLOR SWIFT LOOKS NOTHING LIKE JACKIE O SO STOP COMPARING THE TWO. c\\u2019mon America aren\\u2019t you sick of her yet? (sorry) 'sample_text_encoded = tokenizer(train_df["text"][0])
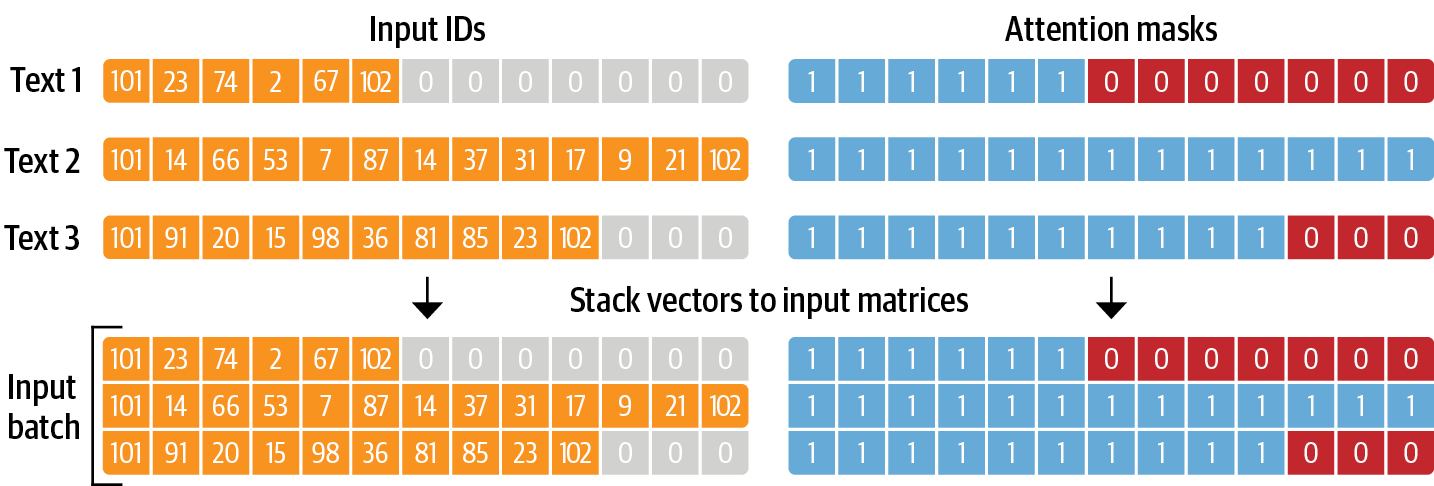
sample_text_encoded{'input_ids': [101, 3100, 1045, 1032, 23343, 24096, 2683, 2213, 3374, 2021, 4202, 9170, 3504, 2498, 2066, 9901, 1051, 2061, 2644, 13599, 1996, 2048, 1012, 1039, 1032, 23343, 24096, 2683, 8202, 2637, 4995, 1032, 23343, 24096, 2683, 2102, 2017, 5305, 1997, 2014, 2664, 1029, 1006, 3374, 1007, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}結果にinput_idsとattention_maskが含まれます。
input_ids: 数字にエンコードされたトークン
attention_mask: モデルで有効なトークンかどうかを判別するためのマスクです。無効なトークン(例えば、PADなど)に対しては、attention_maskを として処理します。
各batchにおいて、入力系列はbatch内最大系列長までpaddingされます。
トークナイザの結果は数字にエンコードされているため、トークン文字列を得るには、convert_ids_to_tokensを用います。
文の開始が[CLS]、文の終了が[SEP]という特殊なトークンとなっています。
tokens = tokenizer.convert_ids_to_tokens(sample_text_encoded.input_ids)
print(tokens)['[CLS]', 'okay', 'i', '\\', 'u2', '##01', '##9', '##m', 'sorry', 'but', 'taylor', 'swift', 'looks', 'nothing', 'like', 'jackie', 'o', 'so', 'stop', 'comparing', 'the', 'two', '.', 'c', '\\', 'u2', '##01', '##9', '##mon', 'america', 'aren', '\\', 'u2', '##01', '##9', '##t', 'you', 'sick', 'of', 'her', 'yet', '?', '(', 'sorry', ')', '[SEP]']
2.2.2データセット全体のトークン化¶
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)dataset.reset_format()dataset_encoded = dataset.map(tokenize, batched=True, batch_size=None)import pandas as pd
sample_encoded = dataset_encoded["train"][0]
pd.DataFrame(
[sample_encoded["input_ids"]
, sample_encoded["attention_mask"]
, tokenizer.convert_ids_to_tokens(sample_encoded["input_ids"])],
['input_ids', 'attention_mask', "tokens"]
).T2.3分類器の実装¶
2.3.1事前学習モデルの導入¶
Transformerライブラリは事前学習モデルの使用ためAutoModelクラスを提供します。
AutoModelクラスはトークンエンコーディングを埋め込みに変換し、エンコーダスタックを経由して最後の隠れ状態を返します。
import torch
from transformers import AutoModel
# GPUある場合はGPUを使う
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(model_ckpt).to(device)最初に、文字列をエンコーダしてトークンをPyTorchのテンソルに変換する必要があります。
結果として得られるテンソルは[batch_size,n_tokens]という形状です。
text = "this is a test"
inputs = tokenizer(text, return_tensors="pt")
print(f"Input tensor shape: {inputs['input_ids'].size()}")Input tensor shape: torch.Size([1, 6])
得られるテンソルをモデルの入力として渡します。
モデルと同じデバイス(GPU or CPU)に設置します。
計算のメモリを減らせるため、
torch.no_grad()で、勾配の自動計算を無効します。出力には隠れ状態、損失、アテンションのオブジェクトが含まれます。
inputs = {k:v.to(device) for k,v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
print(outputs)BaseModelOutput(last_hidden_state=tensor([[[-0.1565, -0.1862, 0.0528, ..., -0.1188, 0.0662, 0.5470],
[-0.3575, -0.6484, -0.0618, ..., -0.3040, 0.3508, 0.5221],
[-0.2772, -0.4459, 0.1818, ..., -0.0948, -0.0076, 0.9958],
[-0.2841, -0.3917, 0.3753, ..., -0.2151, -0.1173, 1.0526],
[ 0.2661, -0.5094, -0.3180, ..., -0.4203, 0.0144, -0.2149],
[ 0.9441, 0.0112, -0.4714, ..., 0.1439, -0.7288, -0.1619]]],
device='cuda:0'), hidden_states=None, attentions=None)
隠れた状態テンソルを見ると、その形状は [batch_size, n_tokens, hidden_dim] であることがわかります。つまり、6つの入力トークンのそれぞれに対して、768次元のベクトルが返されます。
outputs.last_hidden_state.size()torch.Size([1, 6, 768])分類タスクでは、[CLS] トークンに関連する隠れた状態を入力特徴として使用するのが一般的な方法です。このトークンは各シーケンスの始まりに現れるため、次のように outputs.last_hidden_state に単純にインデックスを付けることで抽出できます。
outputs.last_hidden_state[:,0].size()
torch.Size([1, 768])最後の隠れ状態を取得する方法がわかりましたので、データ全体に対して処理を行うため、これまでのステップを関数でまとめます。
そして、データ全体に適用し、すべてのテキストの隠れ状態を抽出します。
def extract_hidden_states(batch):
# Place model inputs on the GPU
inputs = {k:v.to(device) for k,v in batch.items()
if k in tokenizer.model_input_names}
# Extract last hidden states
with torch.no_grad():
last_hidden_state = model(**inputs).last_hidden_state
# Return vector for [CLS] token
return {"hidden_state": last_hidden_state[:,0].cpu().numpy()}dataset_encoded.set_format(type="torch", columns=["input_ids", "attention_mask","label"])
dataset_hidden=dataset_encoded.map(extract_hidden_states, batched=True, batch_size=16)2.3.2AutoModelForSequenceClassificationのファインチューニング¶
transformerライブラリは、ファインチューニングのタスクに応じてAPIを提供しています。
分類タスクの場合、AutoModelの代わりにAutoModelForSequenceClassificationを使用します。
AutoModelForSequenceClassificationが事前学習済みモデルの出力の上に分類器ヘッドを持っており、モデルの設定がより簡単になります。
from transformers import AutoModelForSequenceClassification
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = 3
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight', 'pre_classifier.bias', 'pre_classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
modelDistilBertForSequenceClassification(
(distilbert): DistilBertModel(
(embeddings): Embeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(layer): ModuleList(
(0-5): 6 x TransformerBlock(
(attention): DistilBertSdpaAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(activation): GELUActivation()
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
)
(pre_classifier): Linear(in_features=768, out_features=768, bias=True)
(classifier): Linear(in_features=768, out_features=3, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)inputs = tokenizer("I purchased these boots to use both for everyday wear and when riding my motorcycle.", return_tensors="pt") # pytorch tensorに変換するためにreturn_tensors="pt"を指定
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
print(outputs)SequenceClassifierOutput(loss=None, logits=tensor([[ 0.0746, -0.1015, -0.0341]], device='cuda:0'), hidden_states=None, attentions=None)
2.3.3学習の準備¶
学習時に性能指標を与える必要があるため、それを関数化して定義しておきます。
from sklearn.metrics import accuracy_score, f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}学習を効率化するために、transformerライブラリのTrainer APIを使用します。
Trainerクラスを初期化する際には、TrainingArgumentsという訓練に関する様々な設定値の集合を引数に与えることで、訓練の設定に関する細かい調整が可能です。
from transformers import TrainingArguments
batch_size = 16
logging_steps = len(dataset_encoded["train"]) // batch_size
model_name = "sample-text-classification-bert"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
eval_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error",
report_to="wandb", # wandbに記録
run_name="bert-sentiment-analysis_20260107" # wandbのrun名
)Trainerクラスで実行します。
CUDAエラーのデバッグについて:
CUDA_LAUNCH_BLOCKING=1: GPU操作を同期実行にし、エラーの正確な発生箇所を特定TORCH_USE_CUDA_DSA: デバイス側のアサーションを有効化してより詳細なエラー情報を取得モデルとデータの整合性を事前に確認することで、ラベル数のミスマッチなどの問題を早期発見
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)
trainer.train()preds_output = trainer.predict(dataset_encoded["test"])import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
y_preds = np.argmax(preds_output.predictions, axis=1)
y_valid = np.array(dataset_encoded["test"]["label"])
labels = dataset_encoded["train"].features["label"].names
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)
plt.title("Normalized confusion matrix")
plt.show()
plot_confusion_matrix(y_preds, y_valid, labels)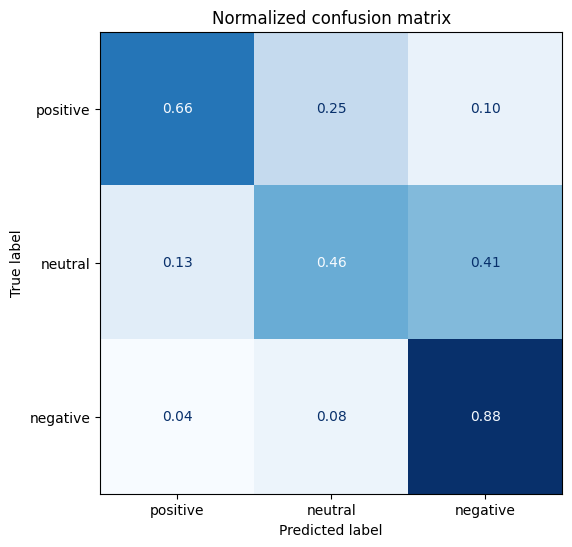
2.4.2モデル保存¶
id2label = {}
for i in range(dataset["train"].features["label"].num_classes):
id2label[i] = dataset["train"].features["label"].int2str(i)
label2id = {}
for i in range(dataset["train"].features["label"].num_classes):
label2id[dataset["train"].features["label"].int2str(i)] = i
trainer.model.config.id2label = id2label
trainer.model.config.label2id = label2idtrainer.save_model(f"./Data/sample-text-classification-bert")2.4.3学習済みモデルの読み込み¶
new_tokenizer = AutoTokenizer\
.from_pretrained(f"./Data/sample-text-classification-bert")
new_model = (AutoModelForSequenceClassification
.from_pretrained(f"./Data/sample-text-classification-bert")
.to(device))サンプルテキストで推論の結果を確認します。
def id2label(x):
label_dict={0:"positive",1:"neutral",2:"negative"}
return label_dict[x]text1="this week is not going as i had hoped"
text2="awe i love you too!!!! 1 am here i miss you"
inputs = new_tokenizer(text1, return_tensors="pt")
new_model.eval()
with torch.no_grad():
outputs = new_model(
inputs["input_ids"].to(device),
inputs["attention_mask"].to(device),
)
outputs.logits
y_preds = np.argmax(outputs.logits.to('cpu').detach().numpy().copy(), axis=1)
y_preds = [id2label(x) for x in y_preds]
y_preds['negative']inputs = new_tokenizer(text2, return_tensors="pt")
new_model.eval()
with torch.no_grad():
outputs = new_model(
inputs["input_ids"].to(device),
inputs["attention_mask"].to(device),
)
outputs.logits
y_preds = np.argmax(outputs.logits.to('cpu').detach().numpy().copy(), axis=1)
y_preds = [id2label(x) for x in y_preds]
y_preds['positive']